Microsoft Fabricの操作ガイド ~基本操作とワークフロー解説~

はじめに
本記事では、 Microsoft Fabric をこれから使い始める方に向けて、基本的な操作方法を紹介していきます。
Microsoft Fabricとは、データ分析に必要な機能を一つに統合した、”エンドツーエンドのSaaS型データプラットフォーム”です。
「データ分析に興味はあるけれど、どこから手を付ければよいか分からない」という方にも、
全体像をつかんでもらえることを目的としています。
今回は、データ活用における基本的な流れに沿って、以下のステップを順に操作していきます。
- データの取得
- データの加工
- データの可視化
- データのAI分析
それぞれの工程で、Microsoft Fabric上ではどのような操作を行うのか、どんなことができるのかを解説していきます。
Microsoft Fabricの概要について知りたい方は、こちらの記事を参照してください。
・Microsoft Fabricとは? ~基礎からわかる統合データ基盤の全体像~
データの取得
-
ワークスペース (Workspace) の作成
“ワークスペース”とは、Fabricで扱うあらゆるデータや成果物をまとめて管理するための 作業部屋 のようなものです。
Fabric内のすべての機能は、ワークスペースの中で利用・管理されます。① Fabricポータルの画面から、[+新しいワークスペース]を選択
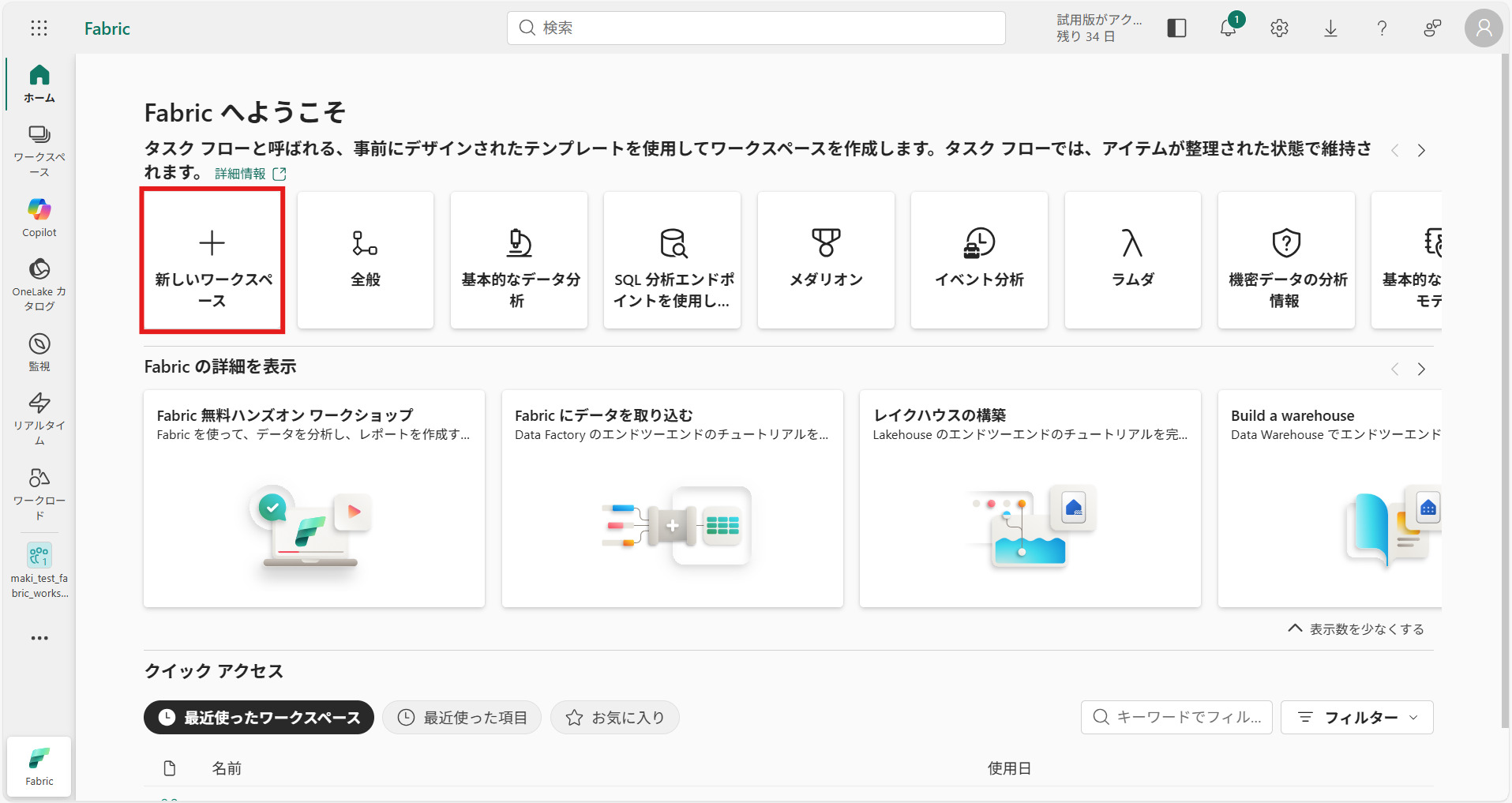
② 作成画面が表示されるので、必須項目を入力して[適用]を押下
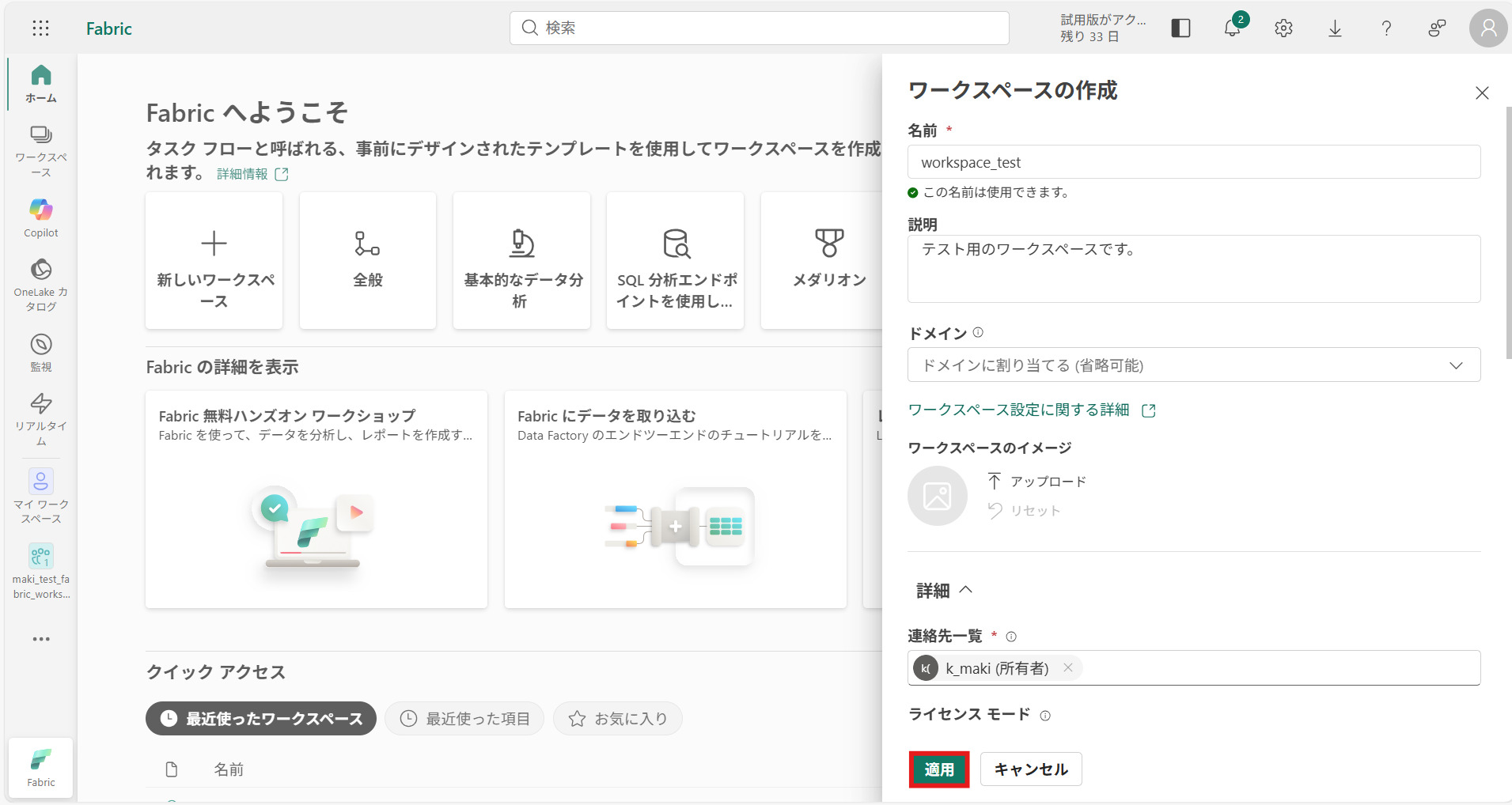
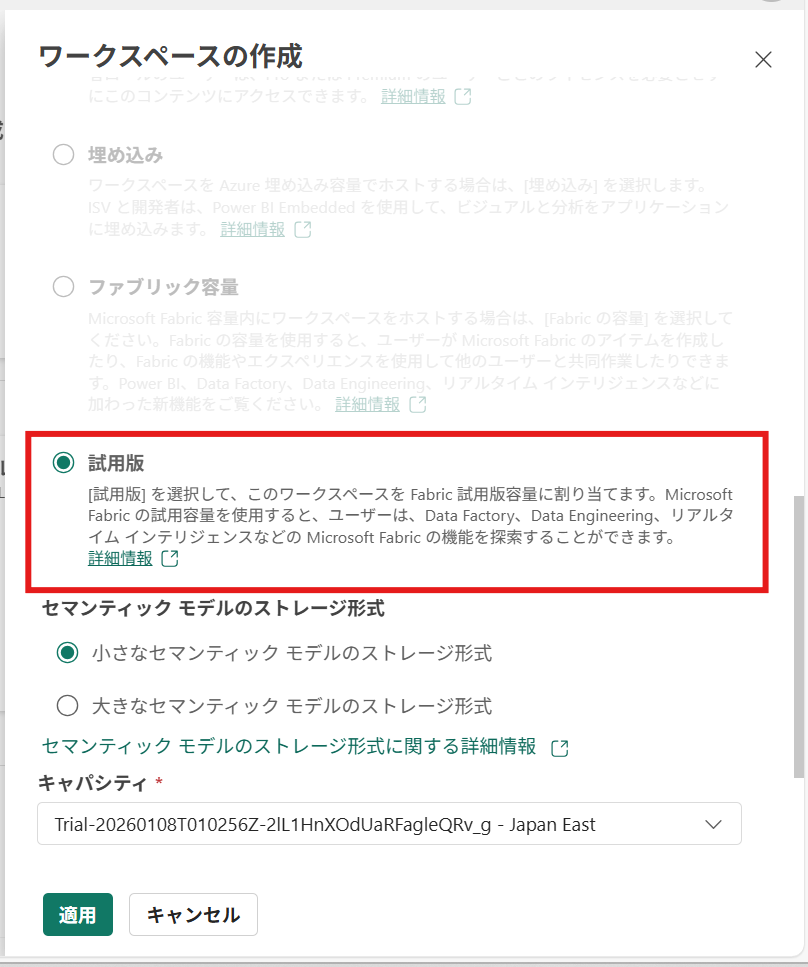
※ライセンスモードは「試用版」を選択する
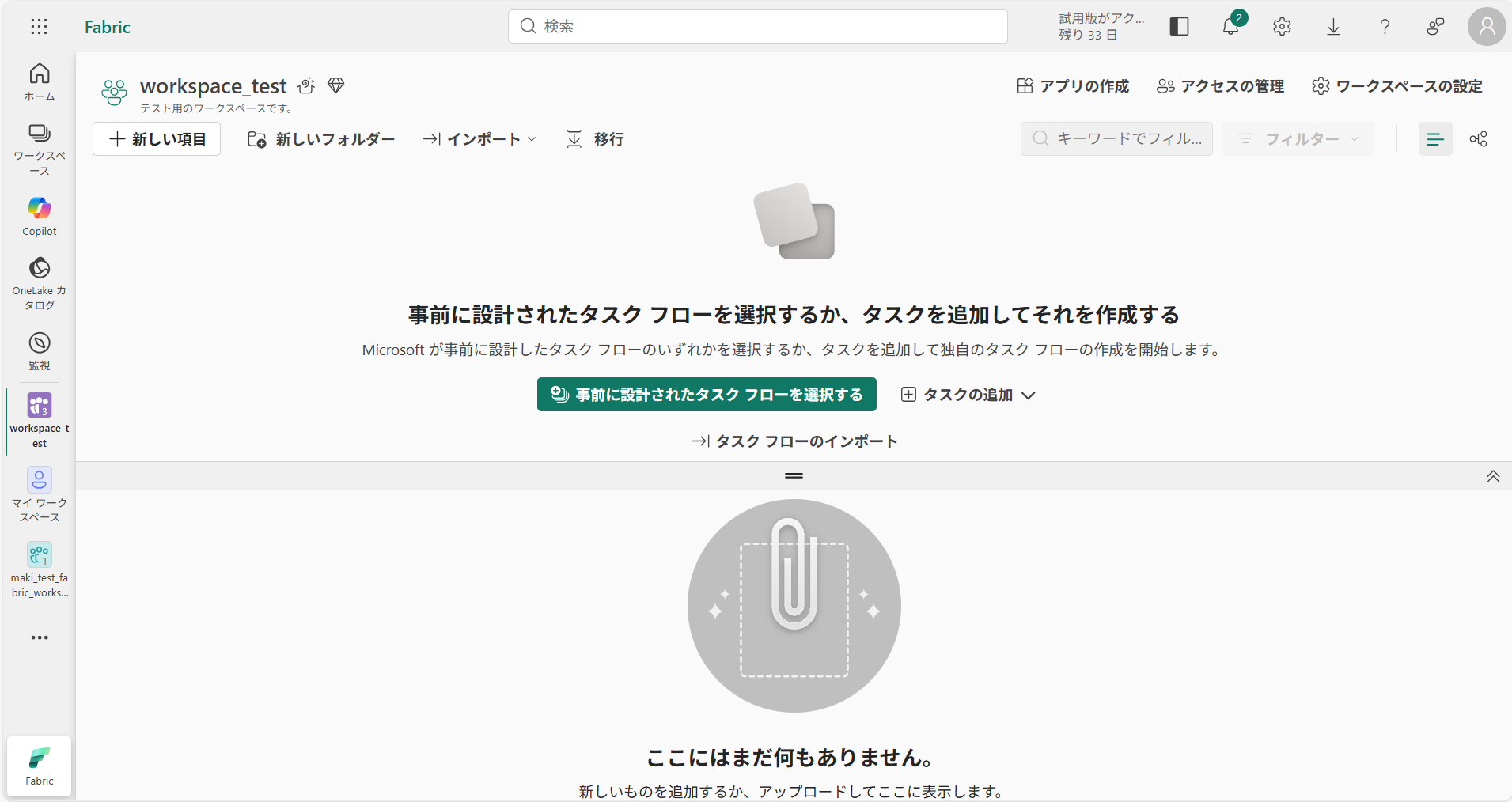
作成後はこのような画面に遷移します。
-
レイクハウス (Lakehouse) の作成
“レイクハウス”とは、構造化 (テーブル形式) および非構造化 (ファイル形式など) データを 一箇所に保存、管理、分析することができるデータリポジトリです。
Microsoft Fabricでは、このレイクハウスを標準かつ中心的なデータ保存・分析基盤としています。
レイクハウスを作成すると SQL分析エンドポイント が自動生成され、 データ検索・クエリなどのSQLが実行できるようになります。① 先ほど作成したワークスペース「workspace_test」を開き、[+新しい項目]を選択して「レイクハウス」と検索し、選択する
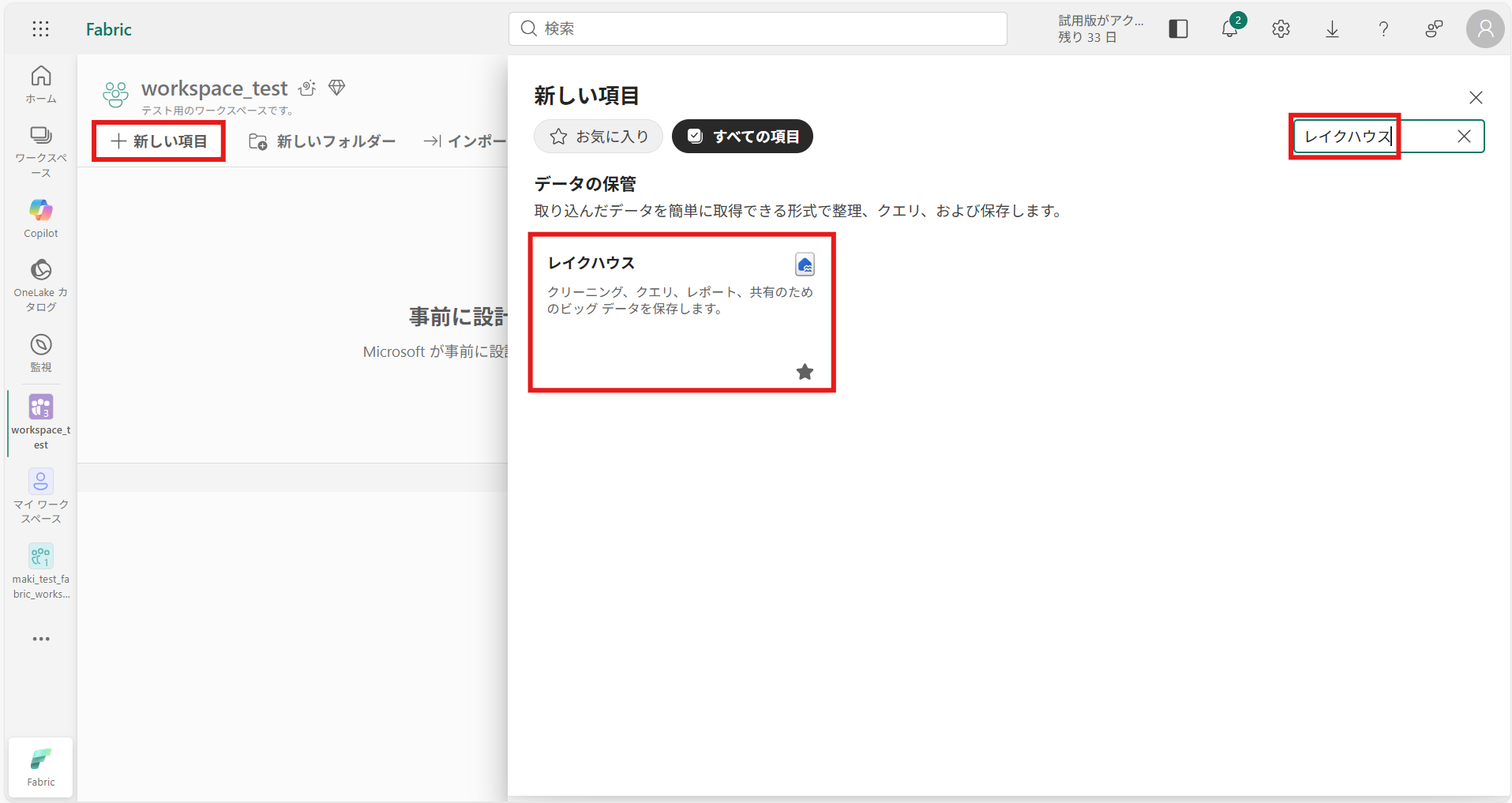
② レイクハウスの名前を入力し、[作成]を押下
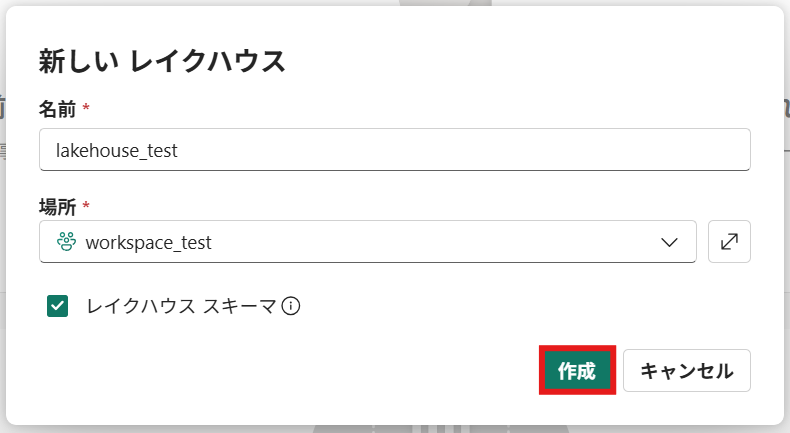
作成後はこのような画面に遷移します。
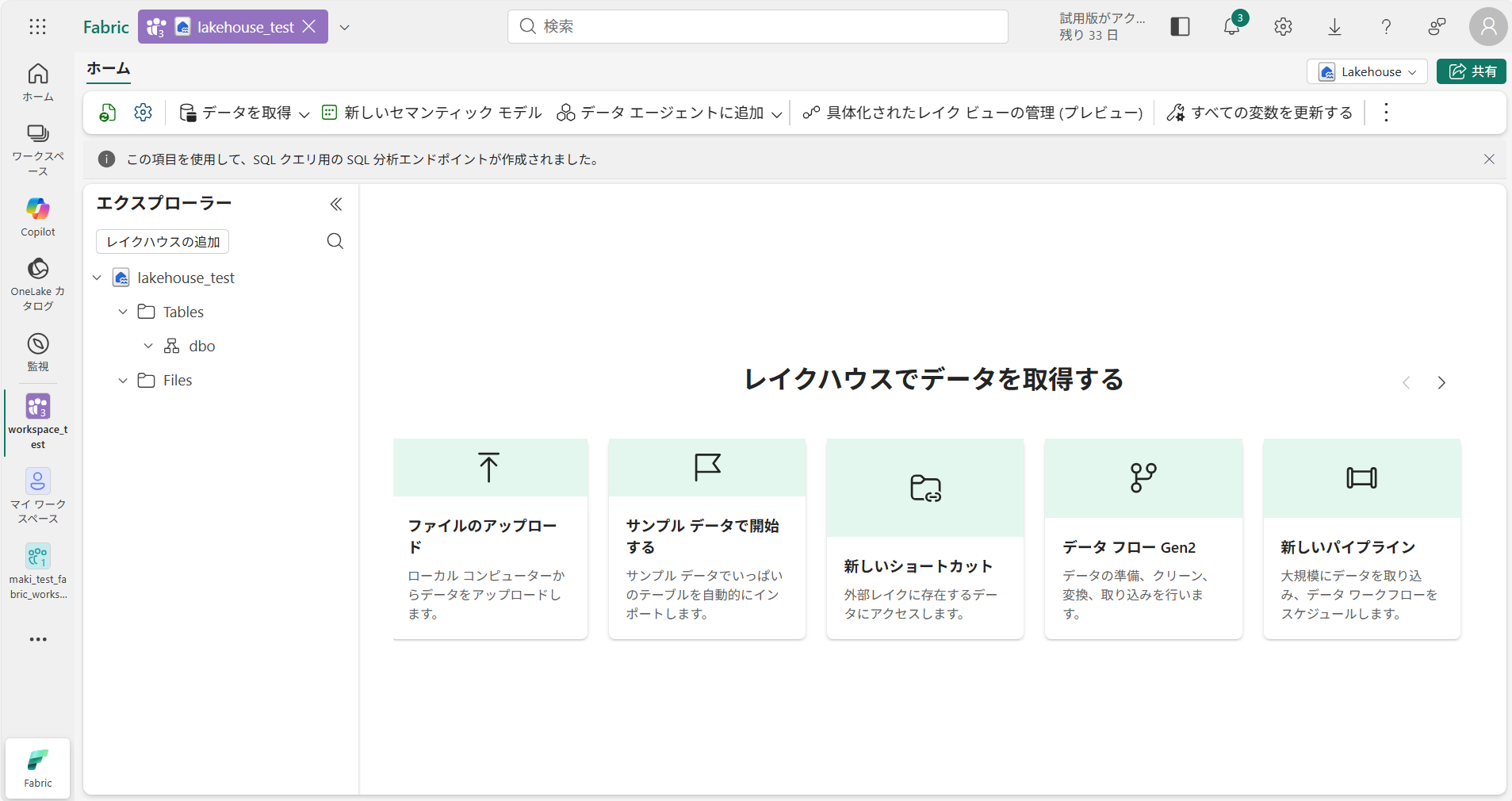
-
パイプライン (Data Pipeline) の作成
“パイプライン”とは、データの取り込み・変換・移動・処理を 一連の流れ(ワークフロー)として定義し、自動実行・管理するための機能です。
① 先ほど作成したレイクハウス「lakehouse_test」画面から、[新しいパイプライン]を選択
※ワークスペース画面から[+新しい項目]を選択して、作成することも可能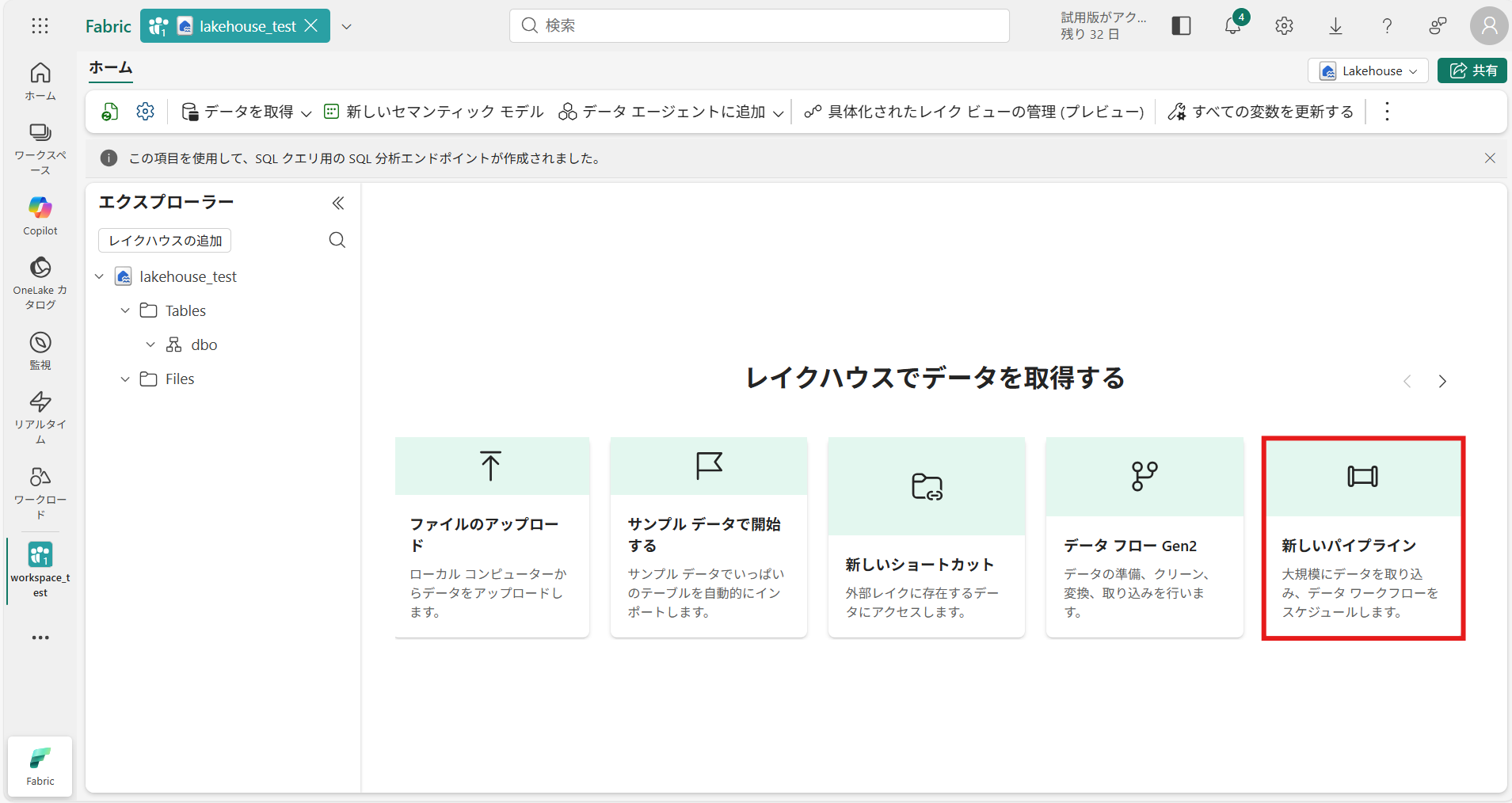
② パイプラインの名前を入力し、[作成]を押下
作成後はこのような画面に遷移します。
-
データ取得
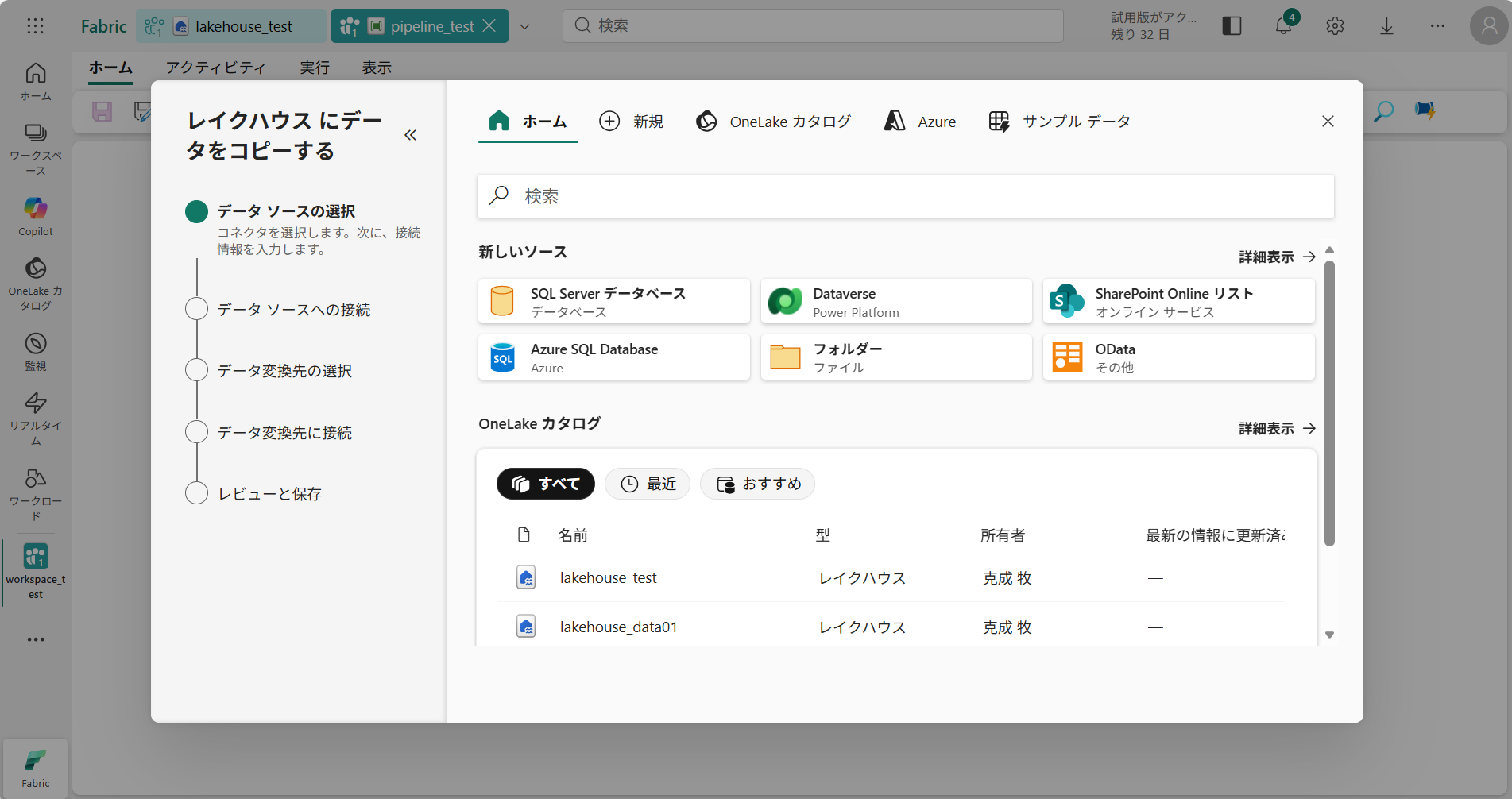
今回はパイプラインから 「サンプルデータ」 を取得してみます。
① データソースの選択 は[サンプルデータ] > [NYC Taxi – Green]を選択する
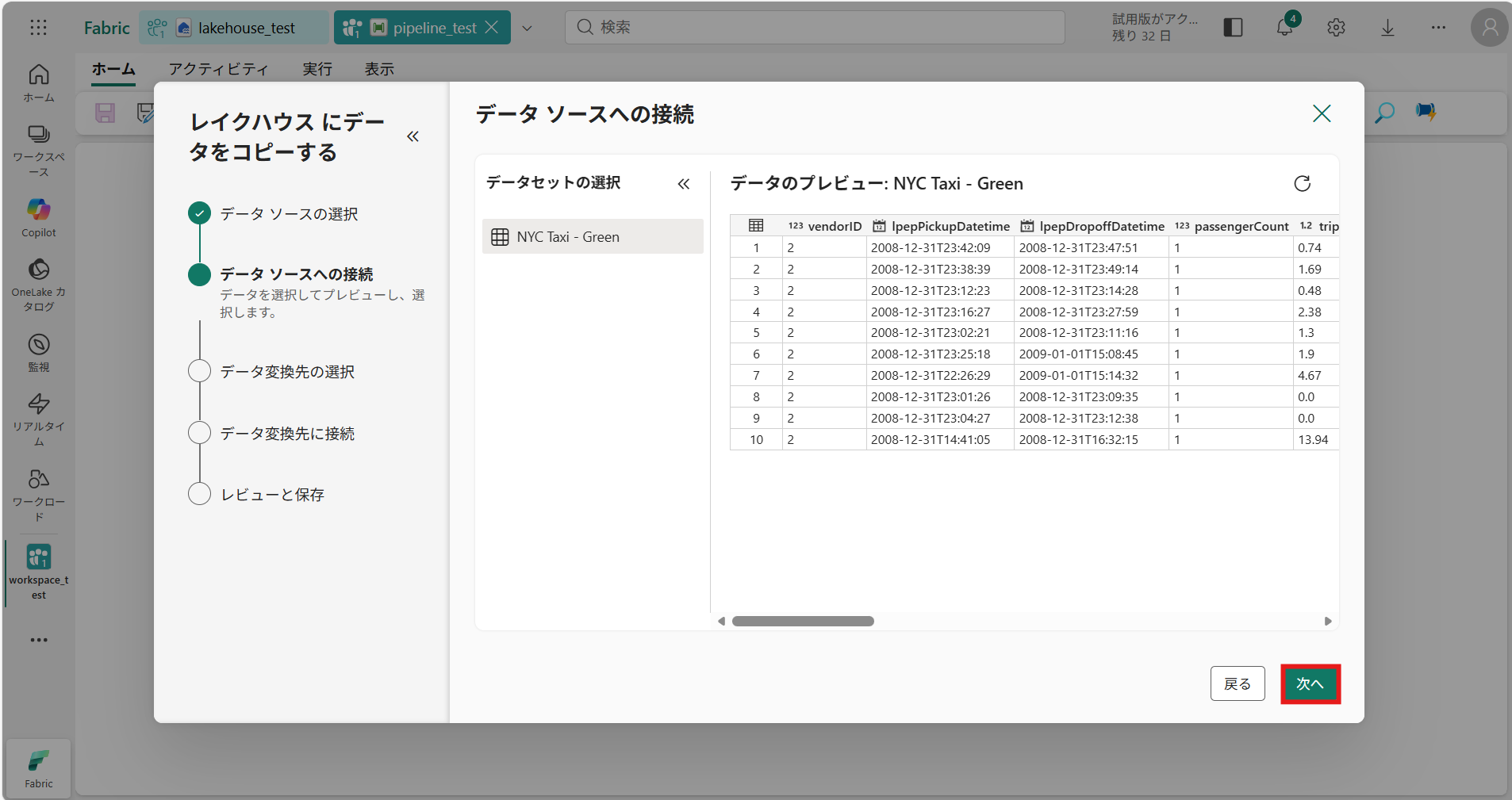
② データソースへの接続 でデータのプレビューができる、 [次へ]を押下
③ データ変換先に接続 では変換先の設定ができる(変換先のフィルダー、テーブル、列マッピングなど)
今回はテーブル名を “dbo.nyc_taxi” に変更し、[次へ] を押下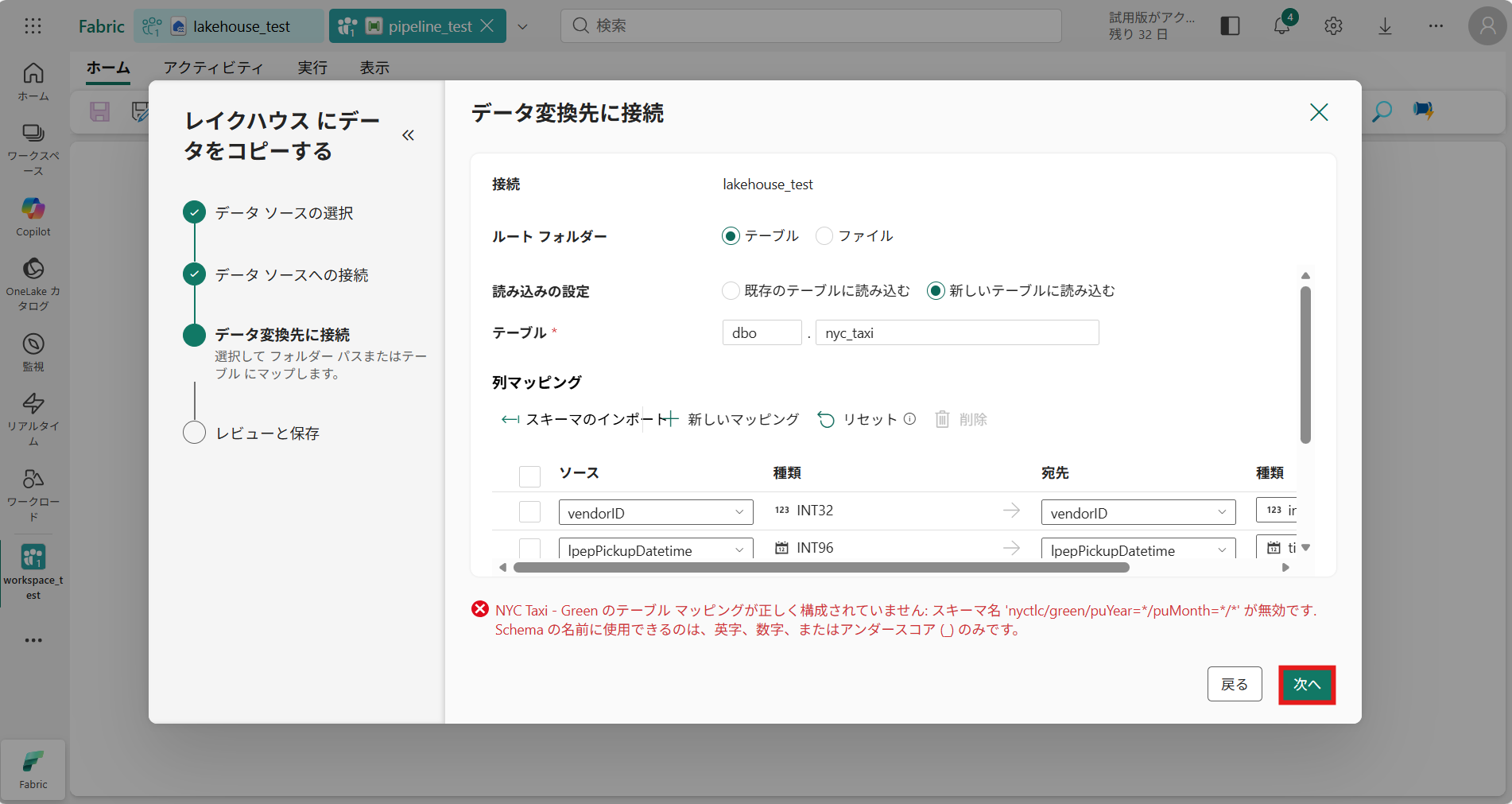
④ レビューと保存 から、テーブルの設定を確認し [保存と実行]を押下
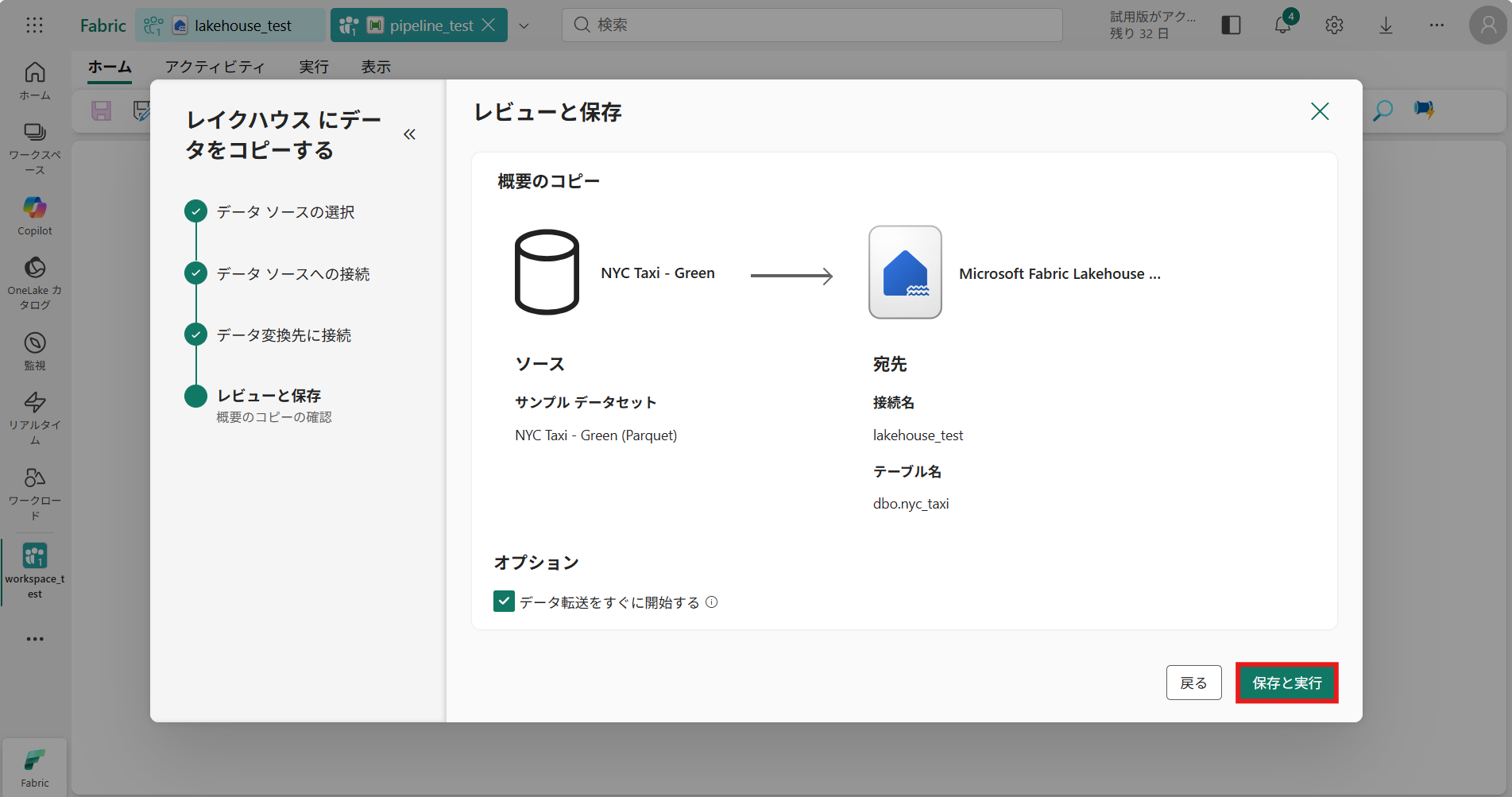
⑤ [保存と実行]を押下後、以下のような画面に遷移する(データ取得の処理中…)
⑥ データ取得完了後にレイクハウスの画面に遷移すると、サンプルデータのテーブルが作成されている
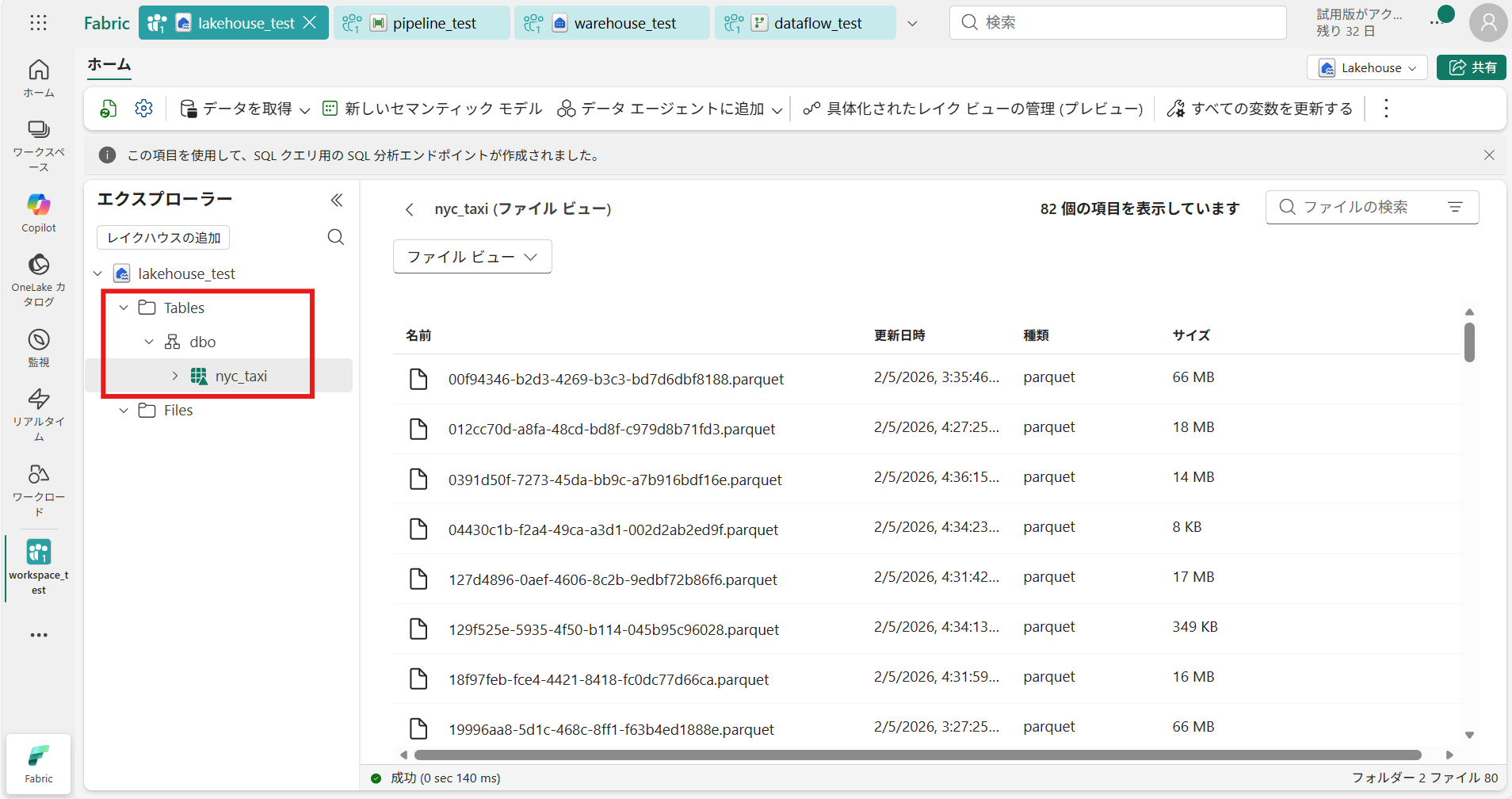
これで、データの取得は完了です。
データの加工
-
ウェアハウス (Warehouse) の作成
“ウェアハウス”とは、SQLをベースとしたクラウドネイティブなエンタープライズ向けデータウェアハウス機能です。
Microsoft Fabric におけるウェアハウスは構造化データ (テーブル形式) 専用のストアとして設計されており、 レイクハウスとは異なりCSV や Parquet などの非構造化データ (ファイル形式) をそのまま格納する用途には向いていません。
その代わりに、スキーマが明確に定義されたデータや、事前に整形・集約された分析用データ を格納することで、 ユーザー分析や BI レポーティングを主目的とした高速なクエリ実行を実現します。① Microsoft Fabricのワークスペースを開き、[+新しい項目]を選択し「ウェアハウス」と検索
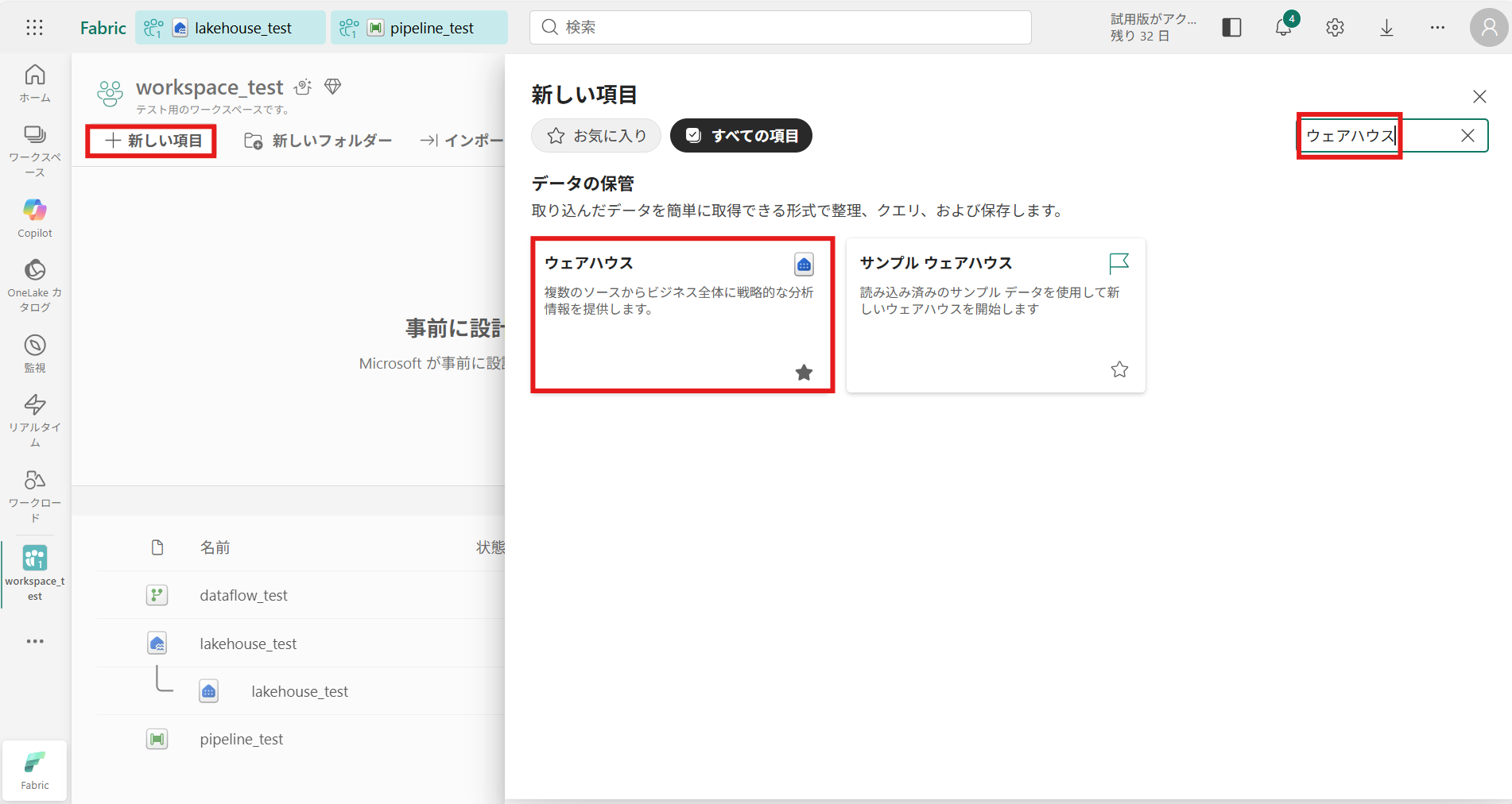
② ウェアハウスの名前を入力し、作成を押下
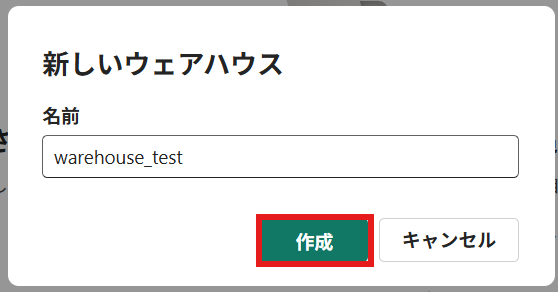
作成後はこのような画面に遷移します。
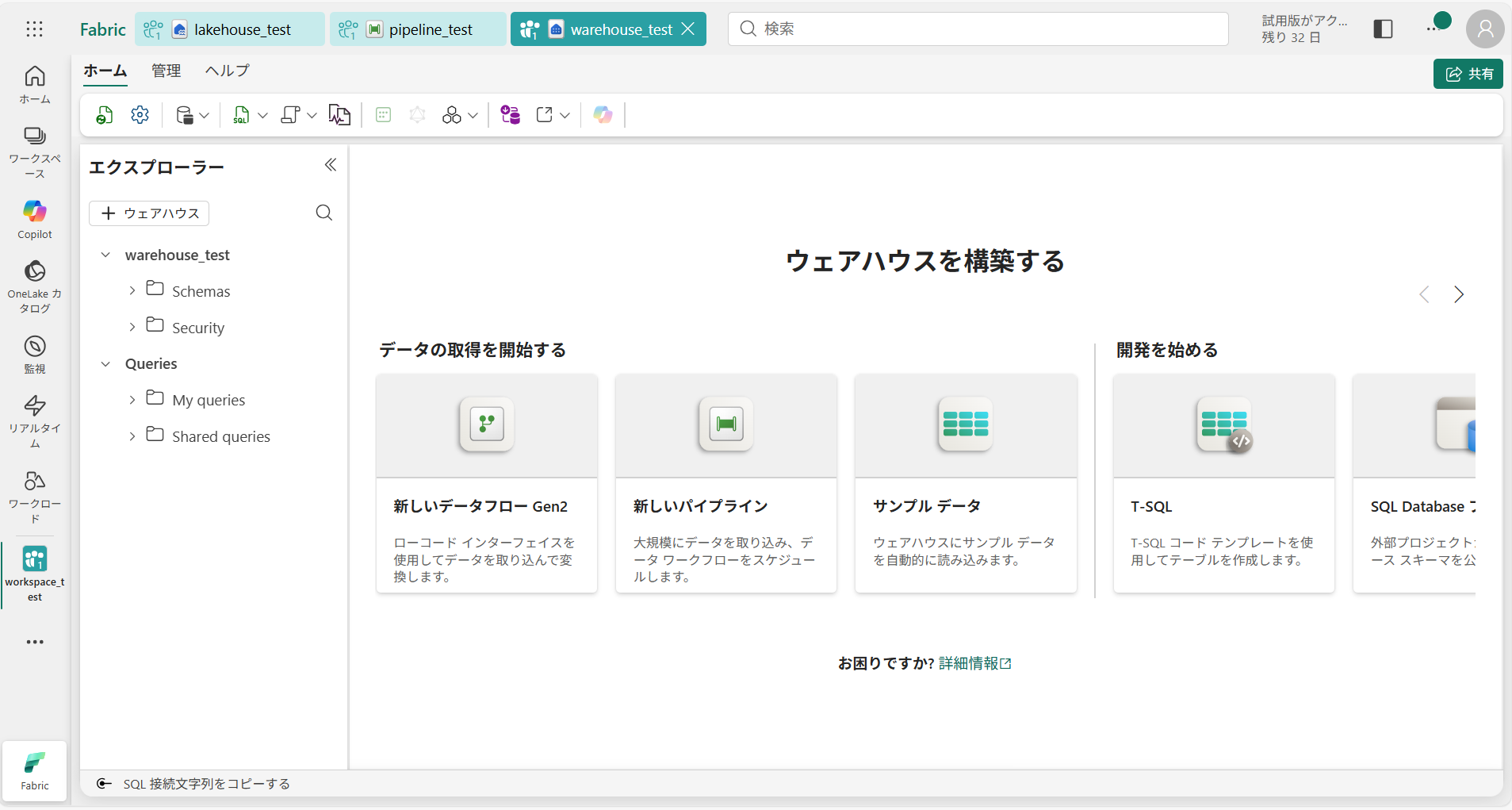
-
データフロー (Dataflow Gen2) の作成
“データフロー”とは、さまざまなデータソースからデータの取り込み、加工、保存が可能な ETL/ELTツール です。
300を超える変換が使用可能で、他のどのツールよりも効率的かつ柔軟にデータを変換することができます。① 先ほど作成したウェアハウス「warehouse_test」画面から、[新しいデータフロー Gen2]を選択
※ワークスペース画面から[+新しい項目]を選択して、作成することも可能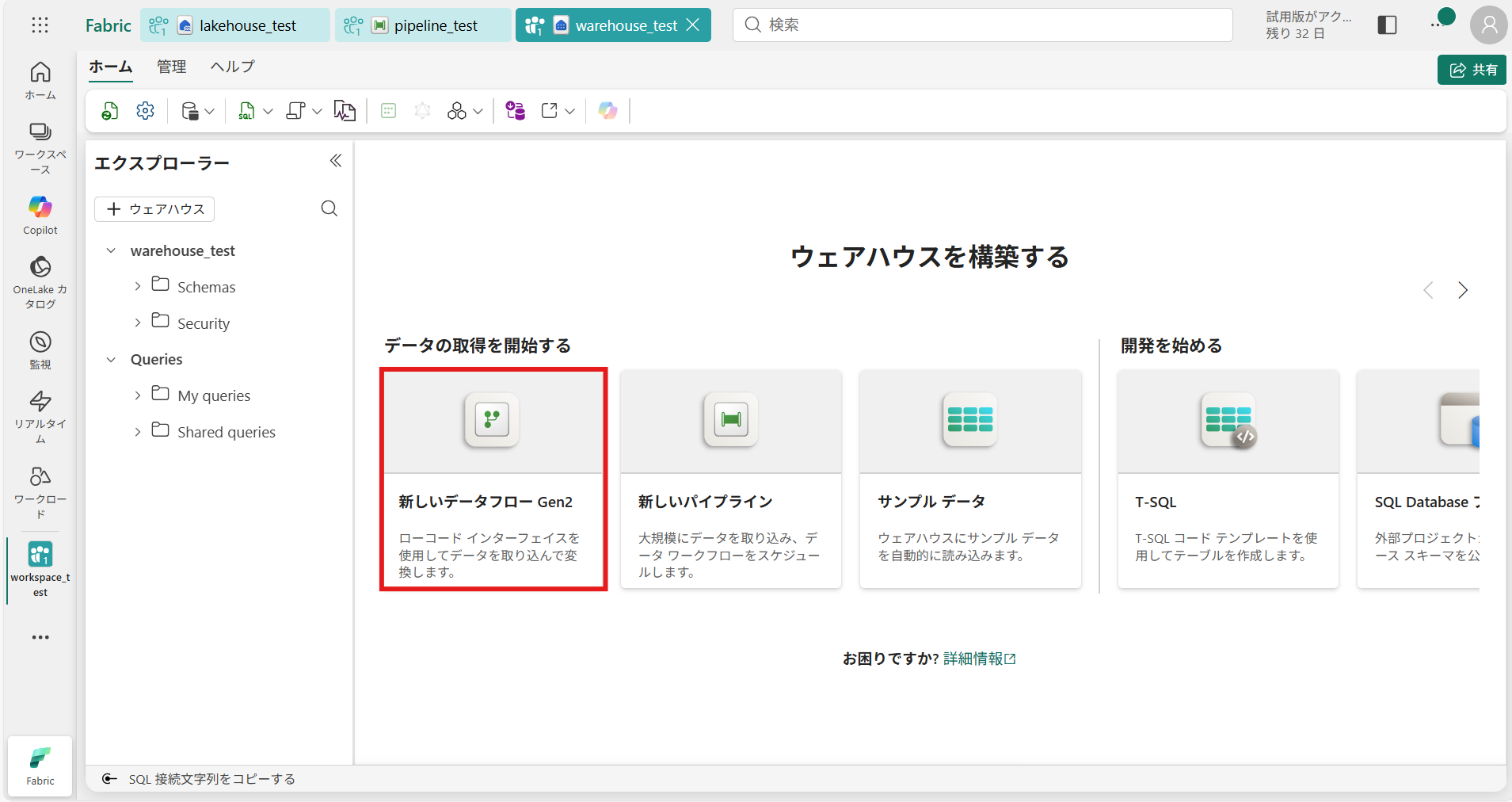
② データフローの名前を入力し、[作成]を押下
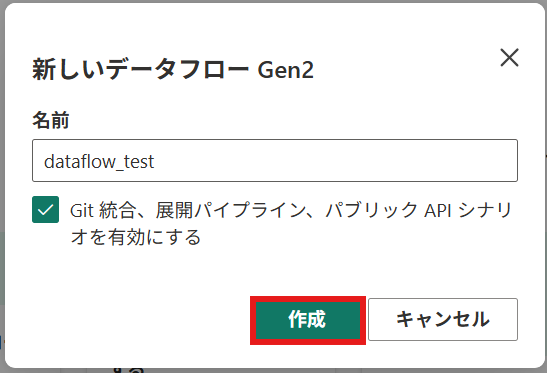
作成後はこのような画面に遷移します。
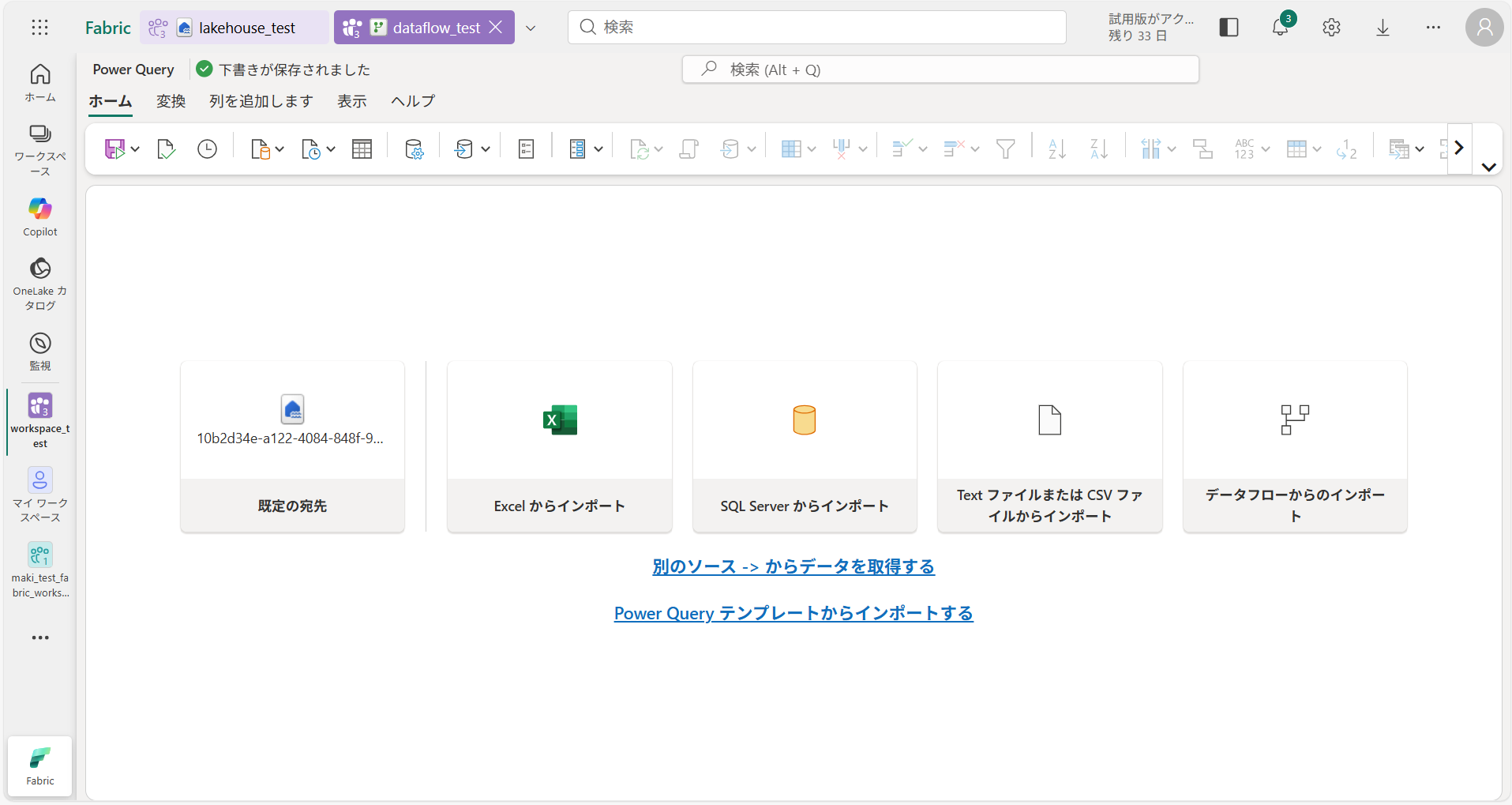
-
データ加工
先ほど作成したデータフロー「dataflow_test」を使って、データを加工していきます。
今回はレイクハウスで取得したサンプルデータ “nyc_taxi” を加工し、ウェアハウスに取り込んでいきます。① [別のソース->からデータを取得する] または、[新しいソース] > [詳細…] を選択
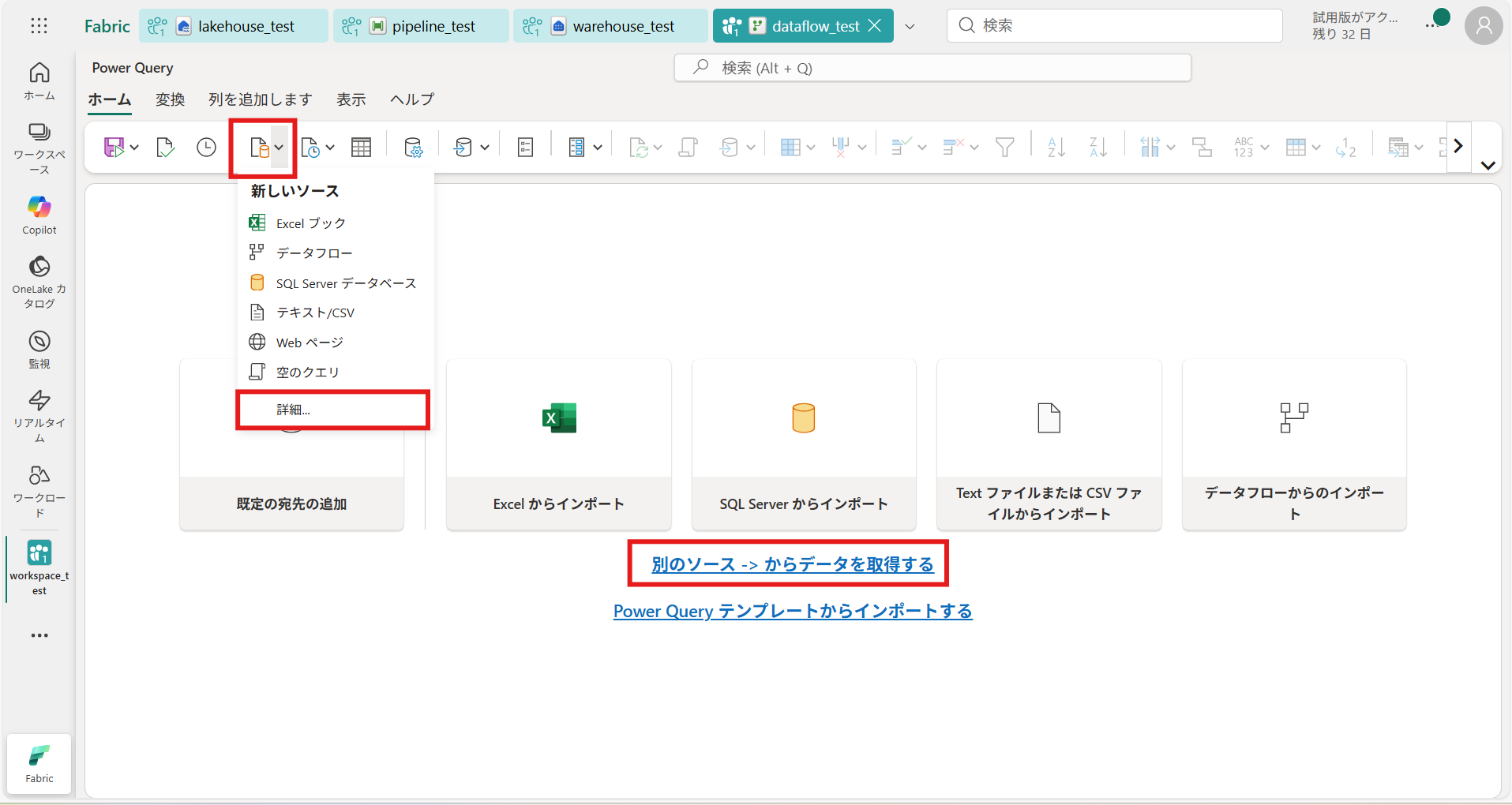
② 接続したいデータソース、データを選択して [作成] を押下(今回は作成したレイクハウスのサンプルデータを取得)
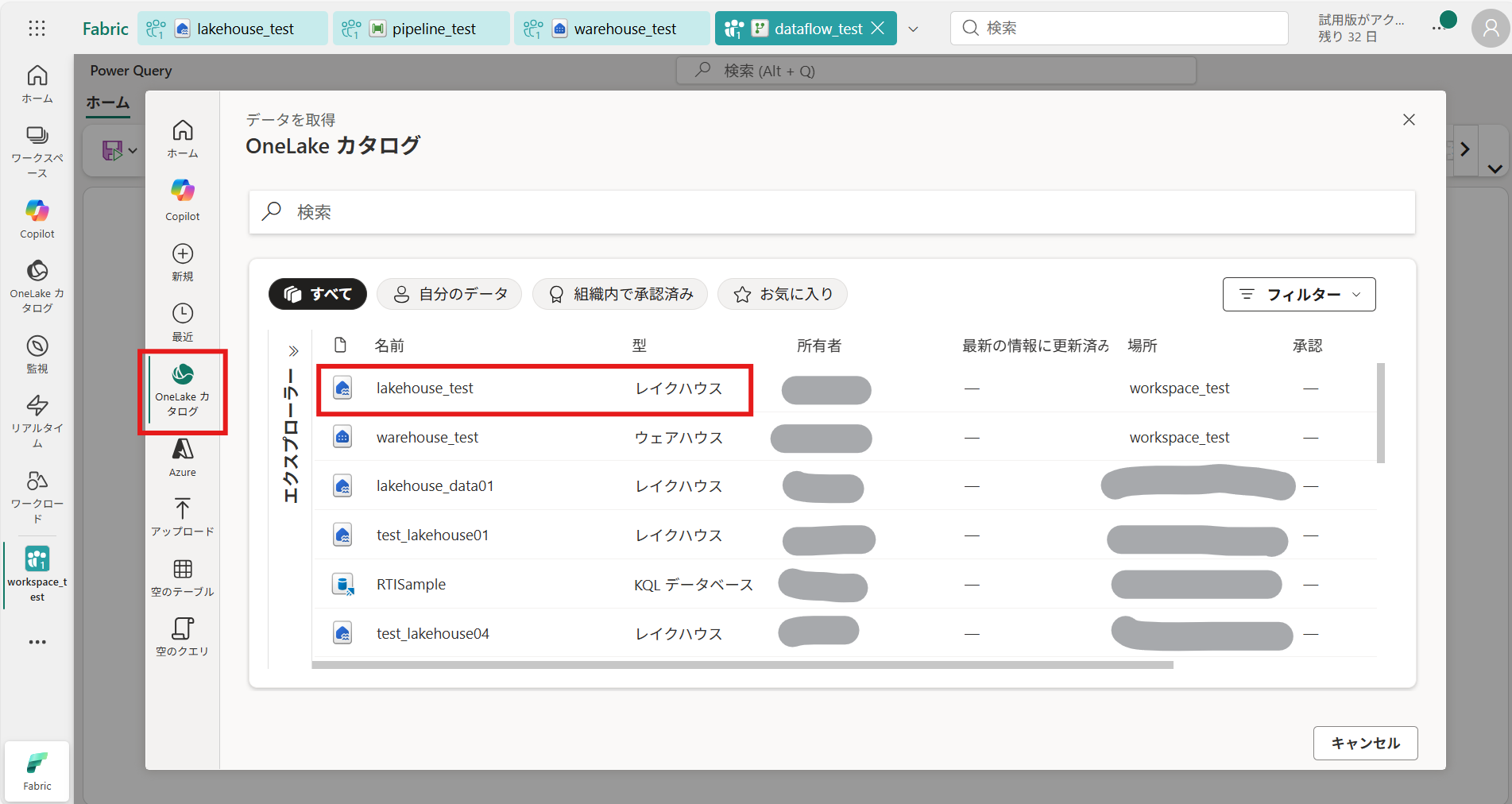
データの選択
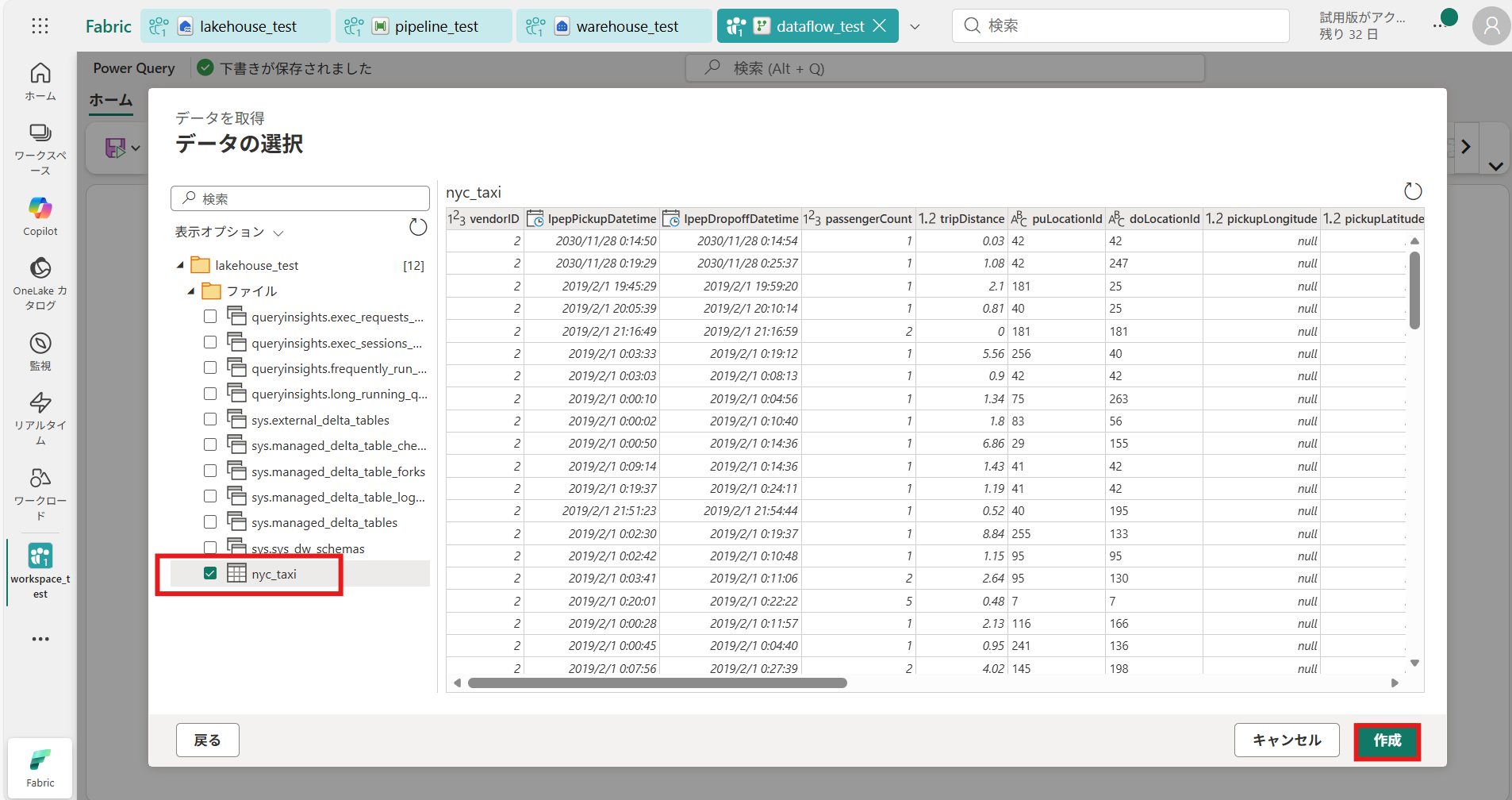
③ 作成後の画面 [ダイアグラムビュー] をONにすることで、テーブル上部にダイアグラムが表示される
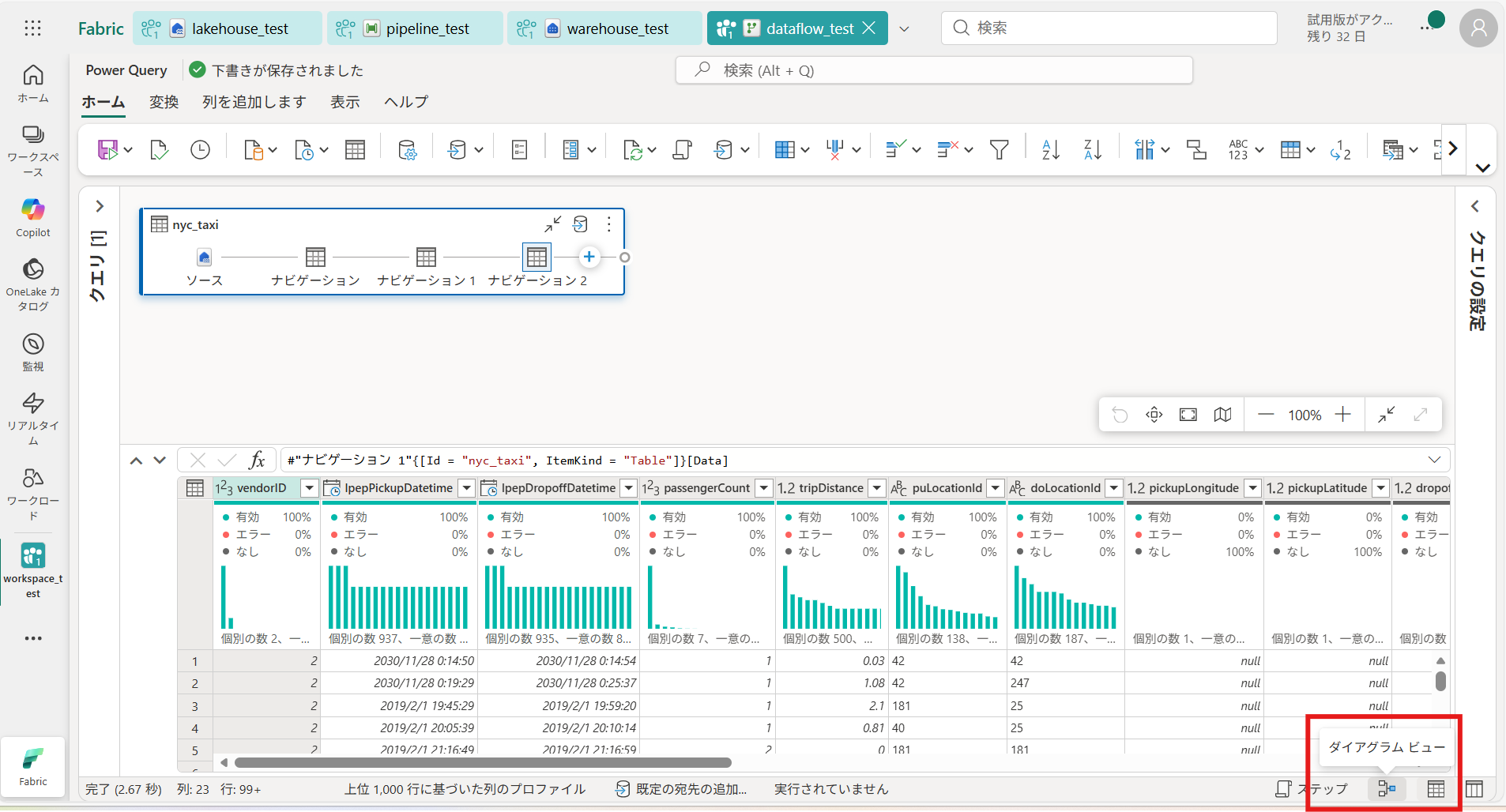
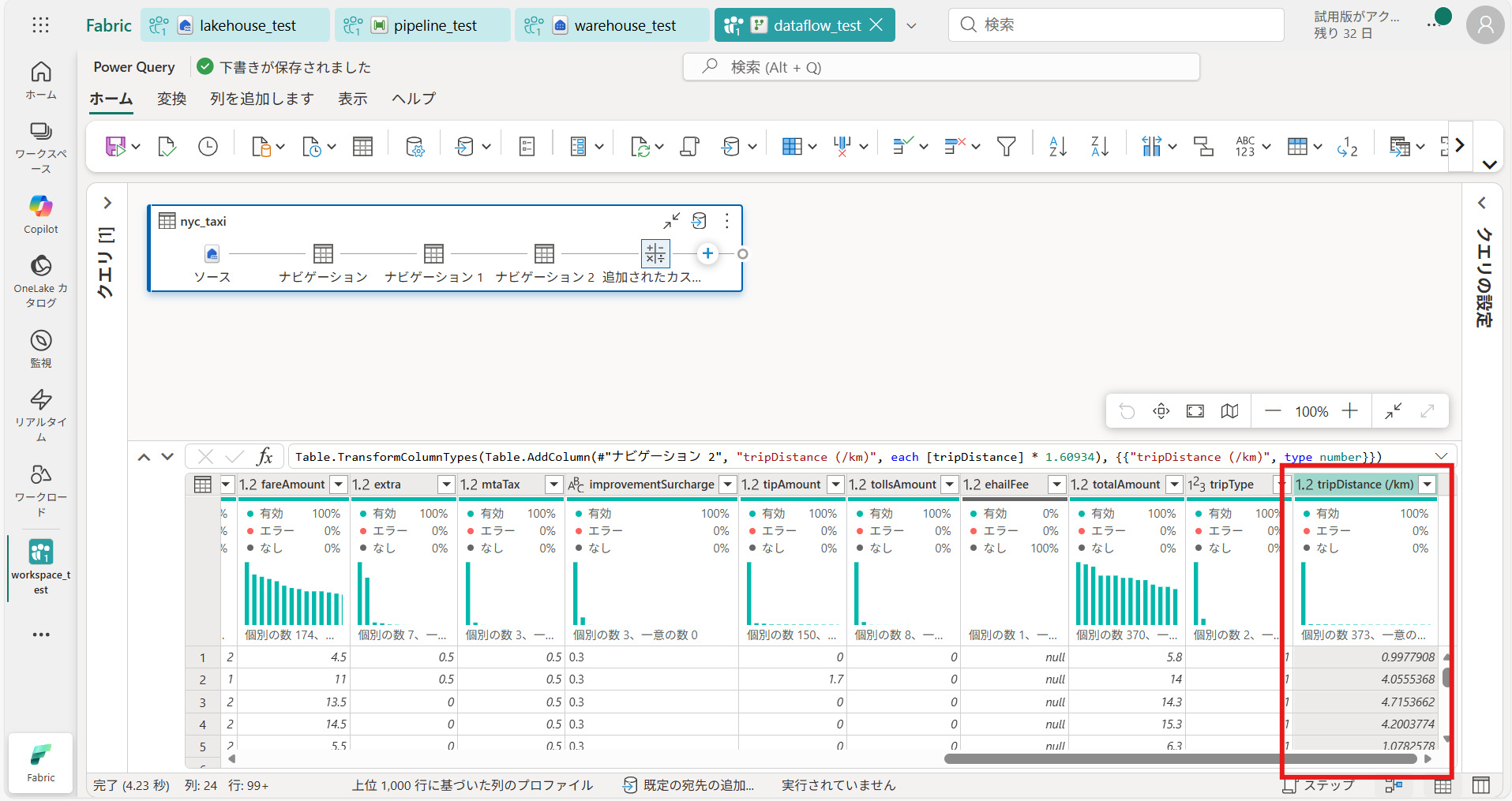
④ ダイアグラムの [+ボタン] から、データの加工ができる(今回は [カスタム列の追加] を選択し、マイルをキロメートル換算した列を追加する)
※他にも グループ化、値の置換、ファイルの分割、AIによる分析(異常値検知やパターン検知)などいろいろな加工が可能
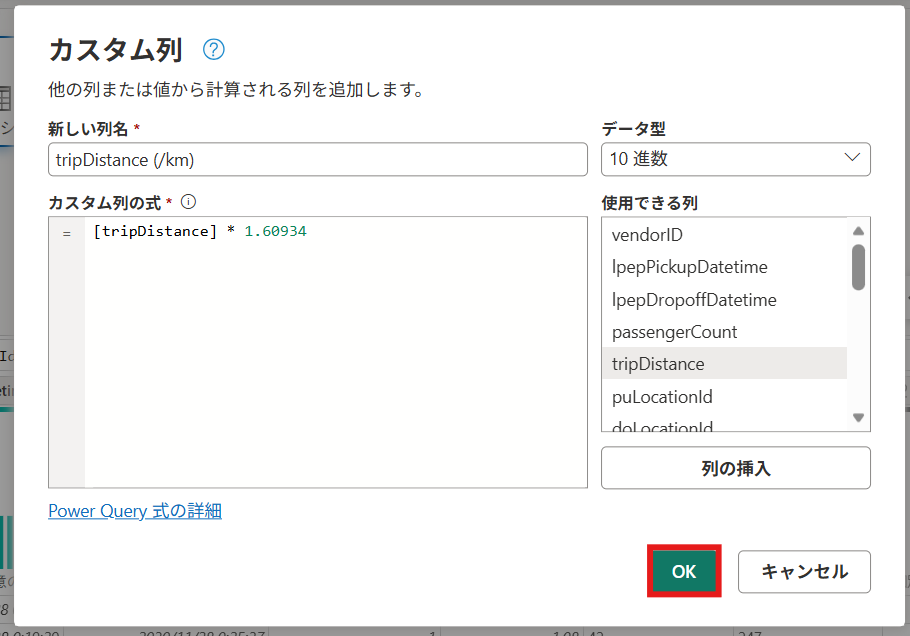
⑤ カスタム列の設定を行い、[OK] を押下
列名:tripDistance (/km)
データ型:10進法
使用できる列:tripDistance
カスタム列の式:= [tripDistance] * 1.60934
⑥ 列が追加されたことを確認して、データの追加は完了
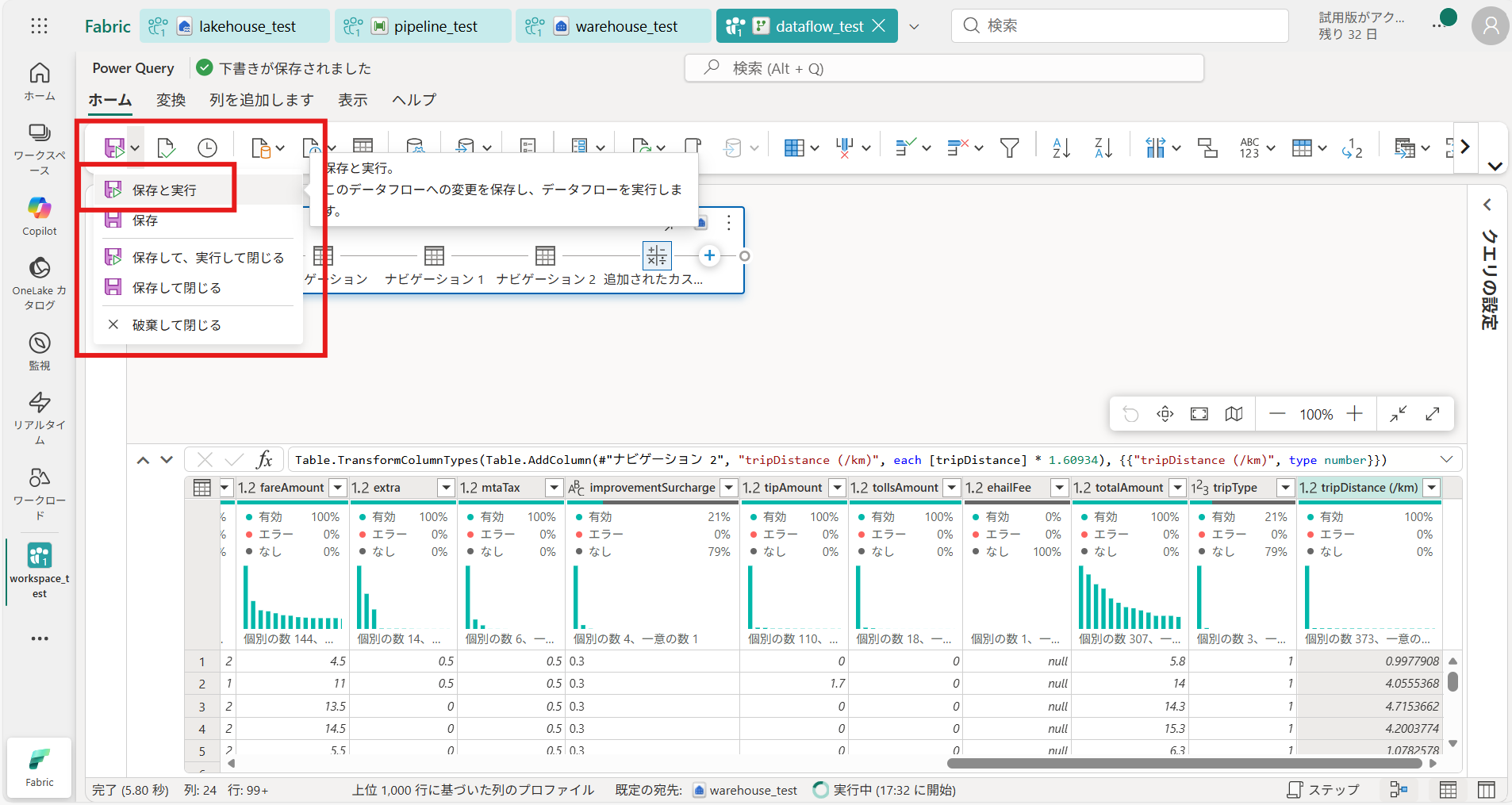
⑦ データの加工が完了したら、先ほど作成したウェアハウス[warehouse_test]に加工後のデータを取り込む [保存と実行] を押下し、データフローを保存、ウェアハウスにデータ変換する
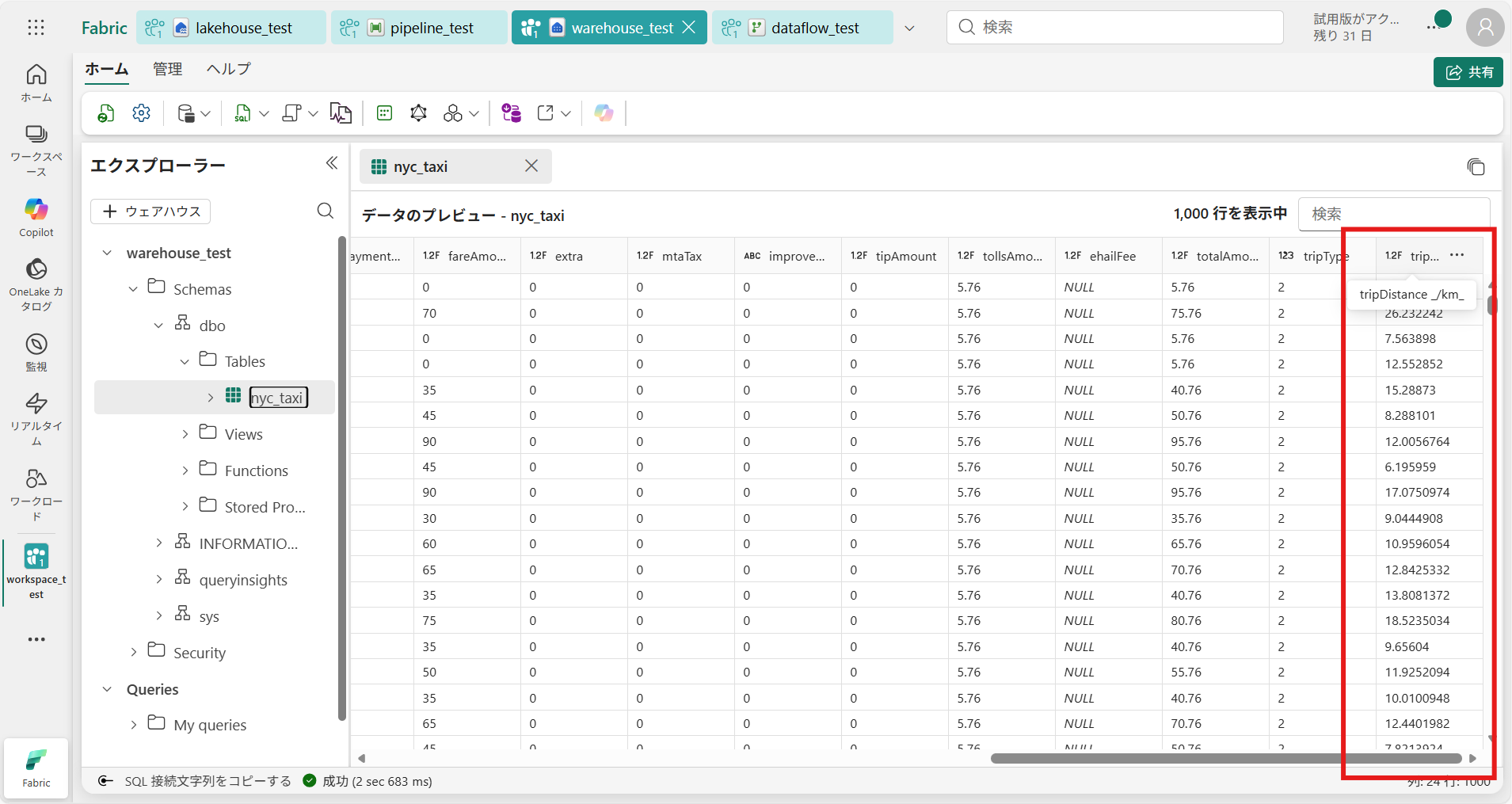
⑧ [保存と実行] の完了後、ウェアハウス [warehouse_test] にデータ加工後のテーブルが作成される
これで、データの加工は完了です。
データの可視化
Microsoft Fabricでは、データの可視化には Power BI の機能を活用します。
Power BI で効果的な可視化を行うためには、まずデータから 「セマンティックモデル」 を作成する工程が必要です。
-
セマンティックモデルの作成
“セマンティックモデル”とは、生データをそのまま扱うのではなく、分析しやすい「意味構造」へと変換したデータモデルのことを指します。
テーブル同士の関係性や指標、計算ロジックをあらかじめ定義することで、データの背景を意識することなく直感的に分析や可視化を行えるようになります。① 加工後のデータが保存されているウェアハウス「warehouse_test」画面から、[新しいセマンティックモデル]を選択
※ワークスペース画面から[+新しい項目]を選択して、作成することも可能
② セマンティックモデルの名前、対象のデータテーブルを入力し、[確認]を押下
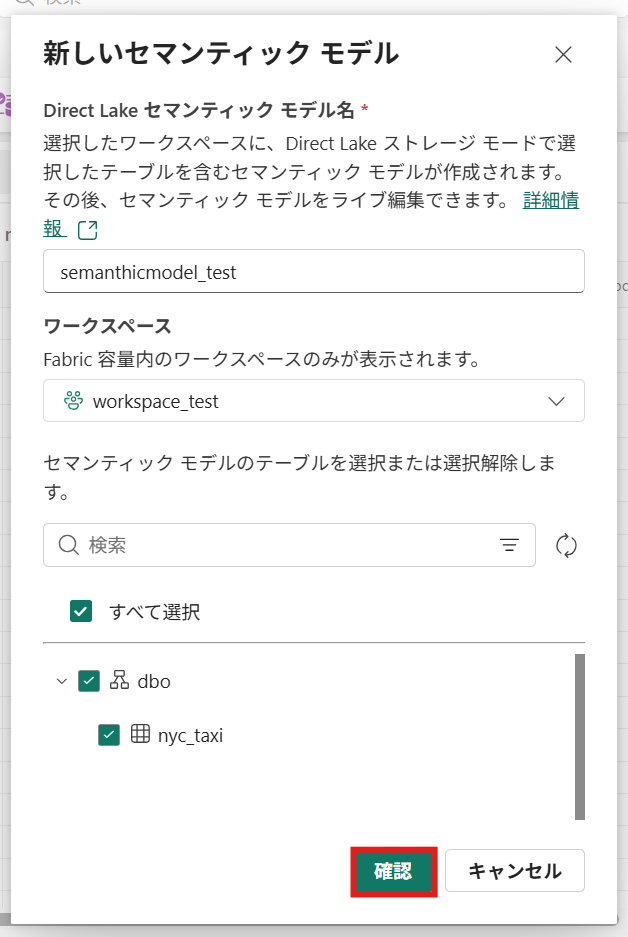
作成後はこのような画面に遷移します。
※データテーブルを複数選択している場合、テーブル同士の「リレーションシップの管理」が可能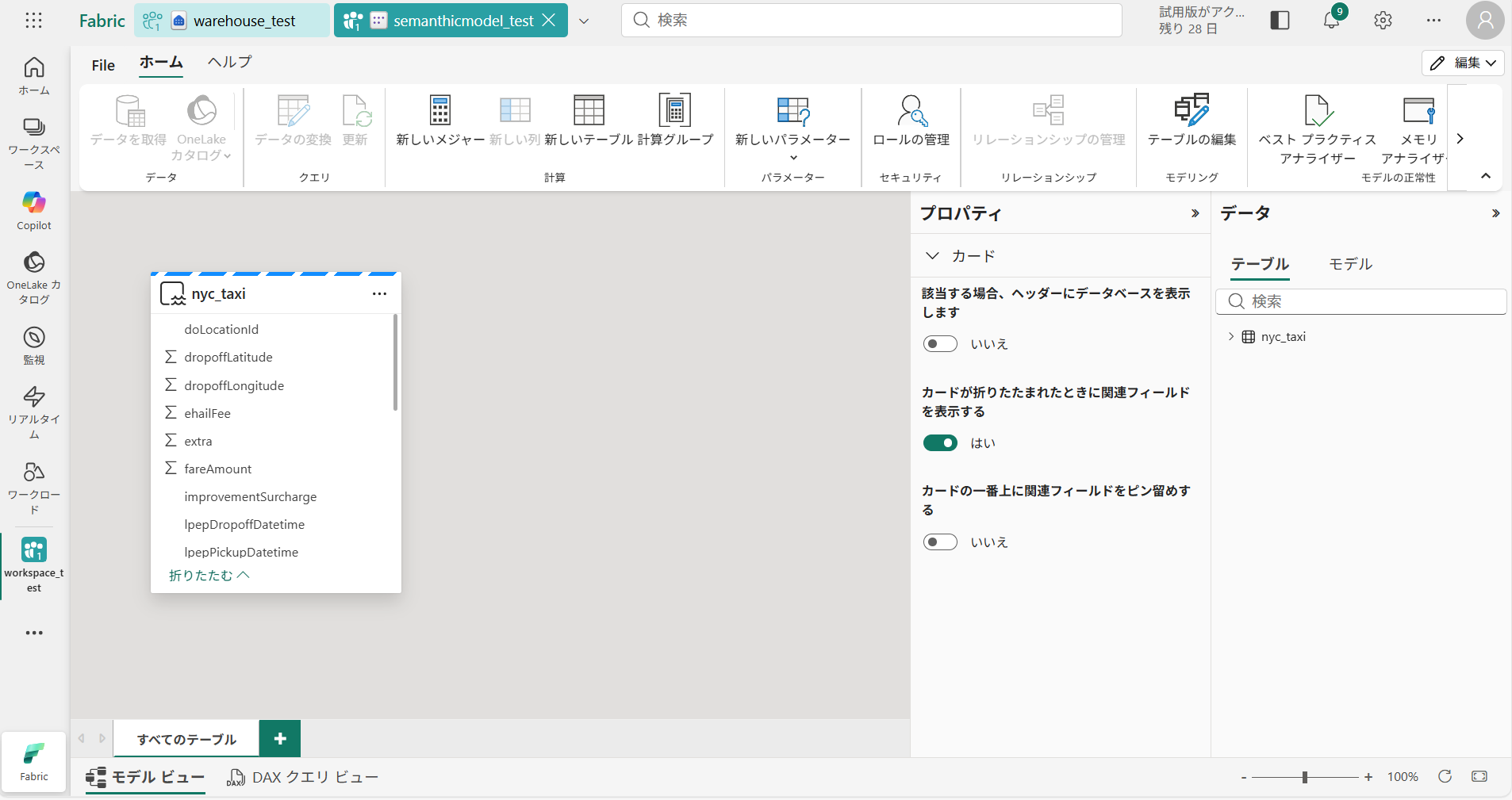
-
レポートの作成
Power BIの可視化機能により、セマンティック モデルを利用してさまざまな “レポート” を作成することができます。
① 作成したセマンティックモデル「semanticmodel_test」画面から、[レポートの自動作成]を選択
※ワークスペース画面から[+新しい項目]を選択して、作成することも可能
② レポート作成中…
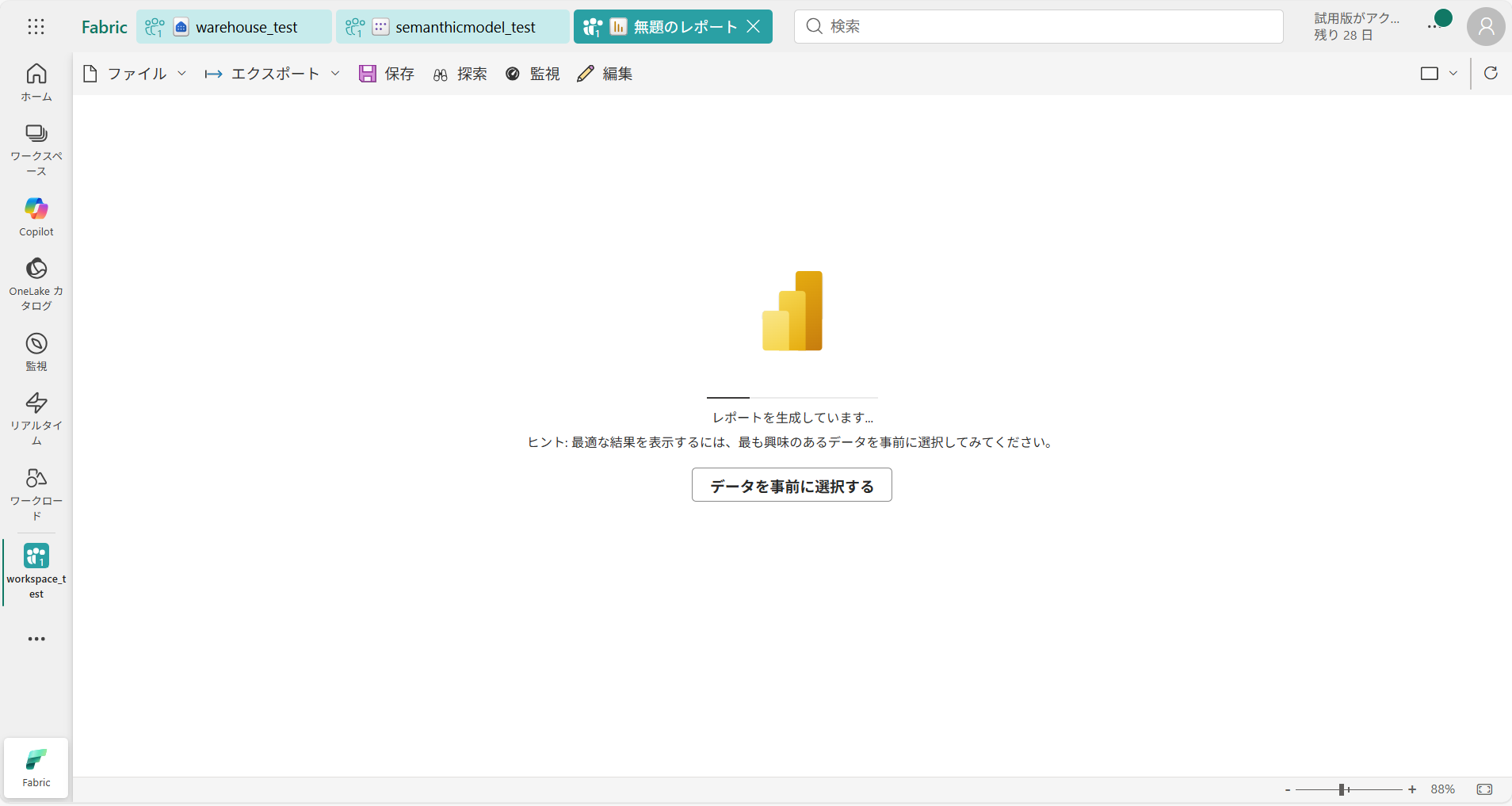
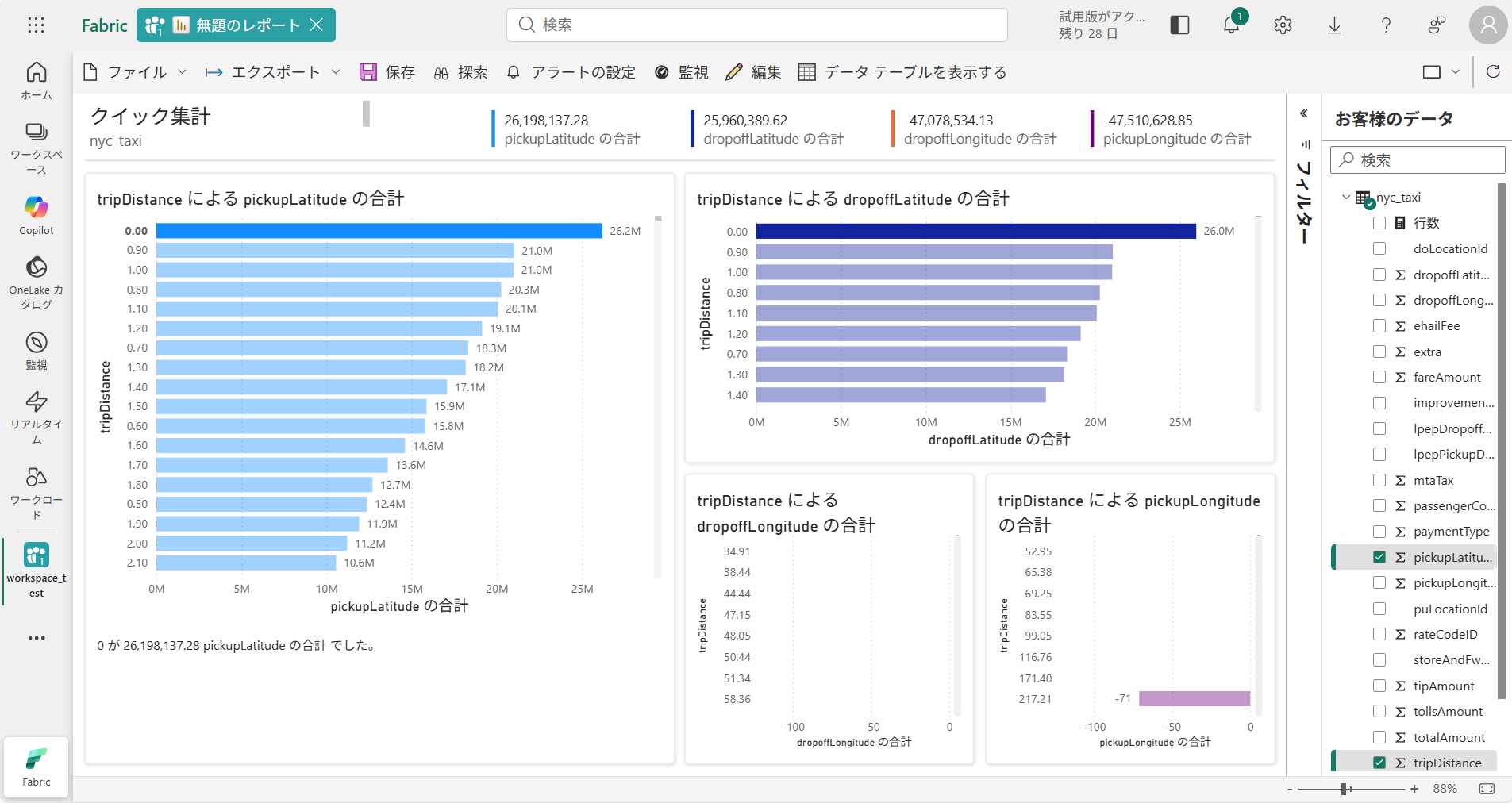
作成後はこのようなレポートの画面に遷移します。
今回は自動作成で実行しましたが、表示する項目を選択してカスタム作成することも可能です。
データのAI分析
Microsoft Fabricでは、AI分析の一環として “MLモデル(機械学習モデル)” を作成・活用することができます。
MLモデルとは、過去のデータから特定のパターンや傾向を学習するようにトレーニングされた学習済みのモデルです。
実体としてはファイルとして保存され、学習によって得られたパラメータやモデル構造が含まれています。
モデルのトレーニングでは、一連のデータセットを入力として、機械学習アルゴリズムを用いてデータ内の特徴や関係性を学習させます。
これにより、数値の傾向や分類ルールなど、人が明示的に定義しなくてもデータから知識を獲得できるようになります。
-
MLモデルの作成
① ワークスペース「workspace_test」を開き、[+新しい項目]を選択して「MLモデル」と検索し、選択する
② MLモデルの名前を入力し、[作成]を押下
③ 作成後はこのような画面に遷移するので、[AutoML で始める] を選択
] ④ データソースの選択で、学習したいデータソースを選択して[次へ]を押下(今回作成したレイクハウス[lakehouse_test]を選択)
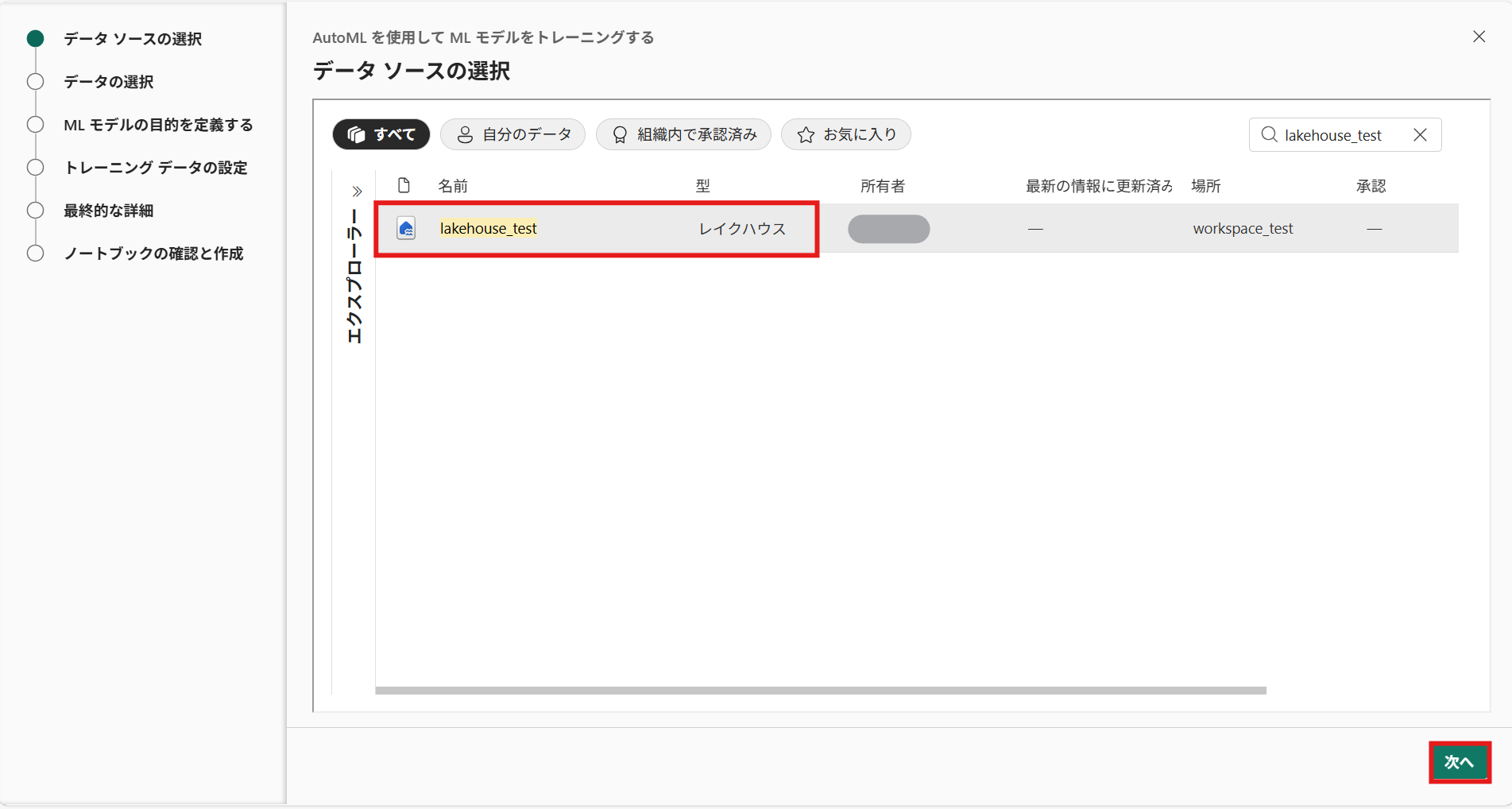
⑤ データの選択で、学習するデータを選択し[次へ]を押下
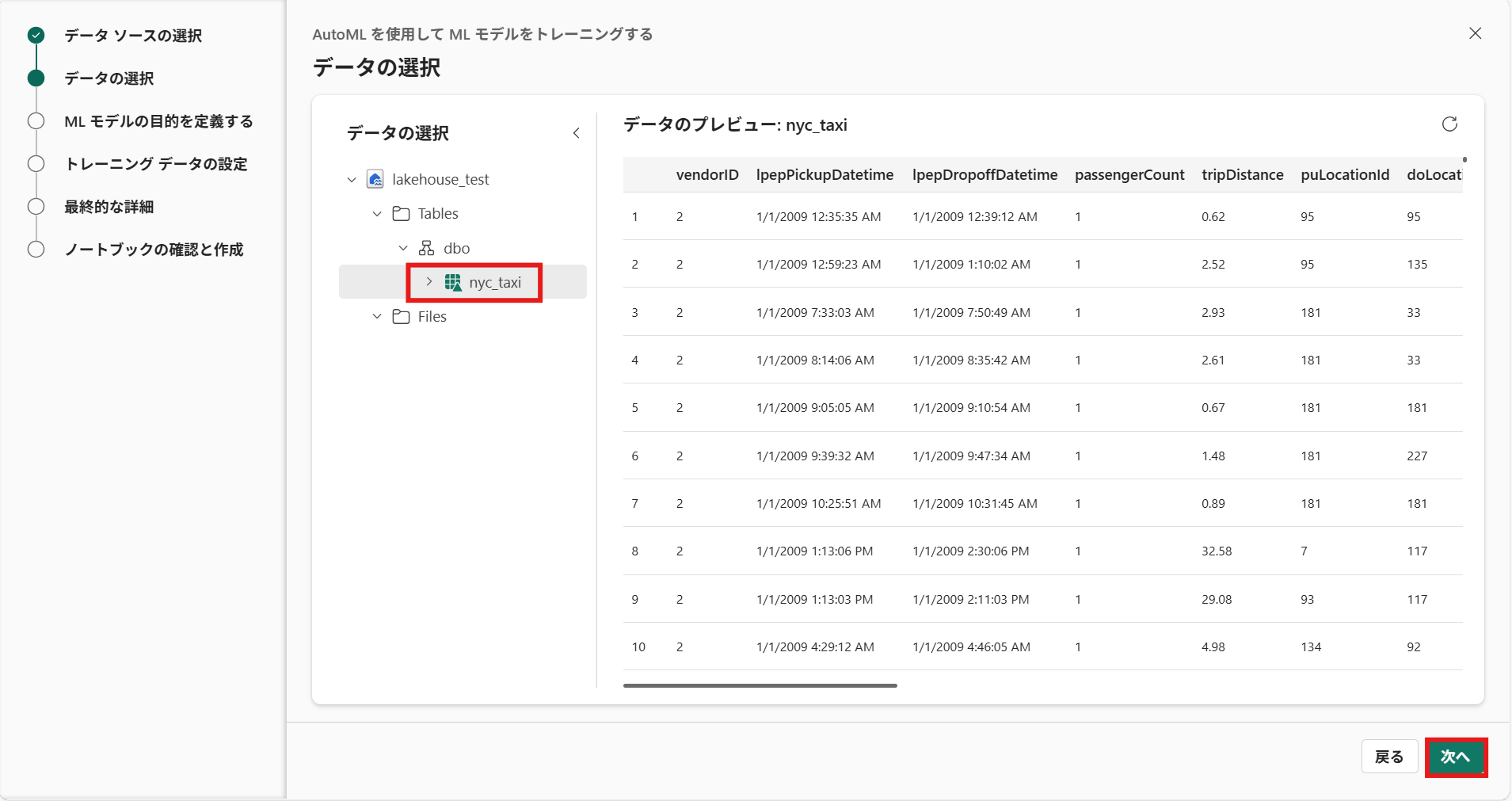
⑥ MLモデルの目的を定義する
今回はMLタスクを 「回帰」、AutoMLモードを「クイックプロトタイプ」に選択して、[次へ]を押下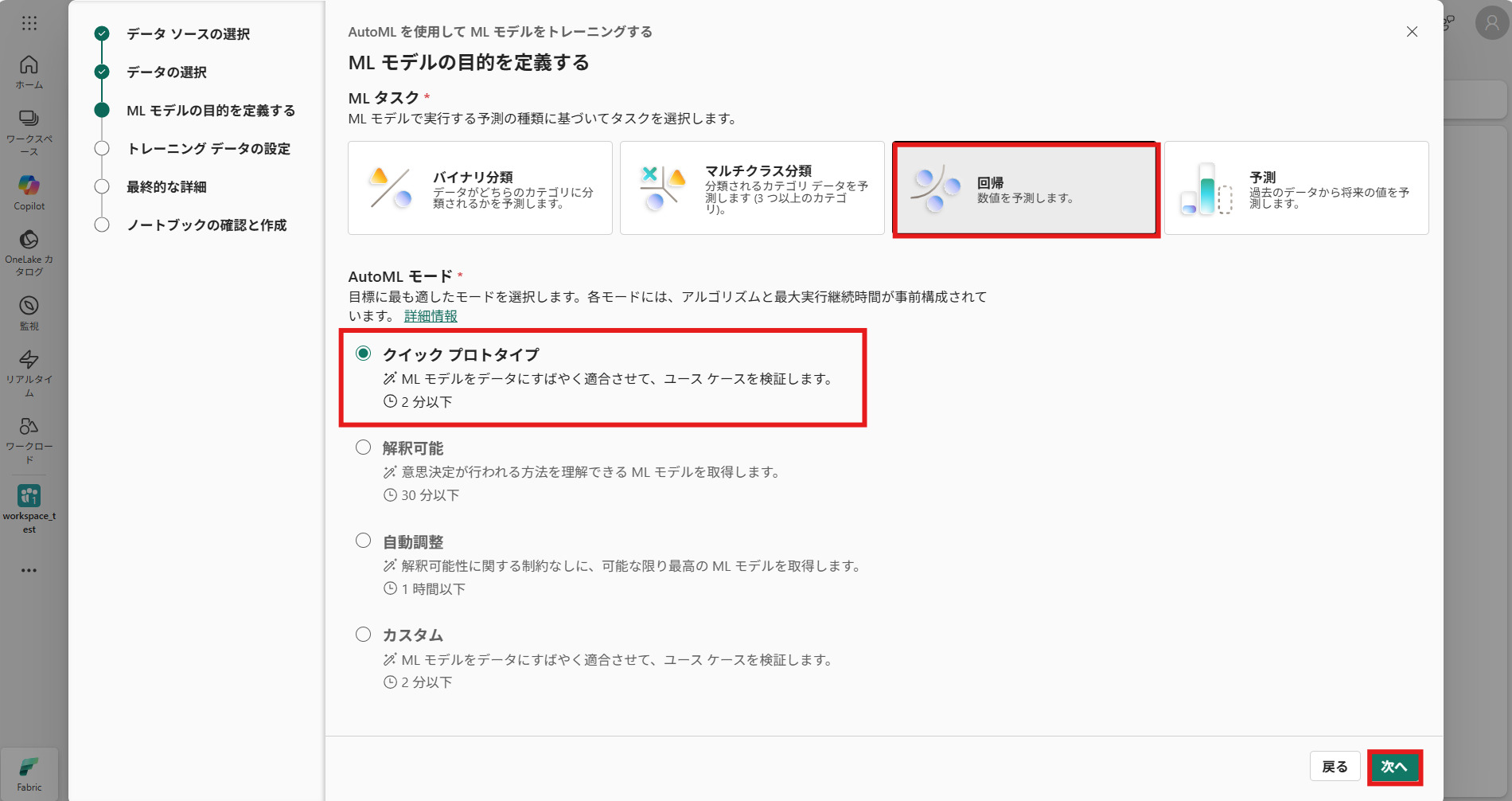
○ MLモデルの概要
-
バイナリ分類:2つのクラスのどちらかを判定するタスク
使用場面の例:解約するかしないか、メールがスパムか否か、顧客が購入するかどうか など
-
マルチクラス分類:3種類以上のカテゴリの中から 1 つを選ぶタスク
使用場面の例:商品カテゴリ分類(食品・家電・衣類など)、問い合わせ内容の分類(請求/技術/契約)、文書やチケットの自動仕分け など
-
回帰:連続した数値を予測するタスク、出力は実数(例:123.45)
使用場面の例:売上金額の予測、顧客の生涯価値(LTV)、配送時間の予測 など
-
予測:時間の流れを考慮して将来の値を予測するタスク、データに 日時(DateTime)列が必須になる → 時間依存性
使用場面の例:月次/日次売上予測、在庫数予測、利用者数・アクセス数の予測 など
⑦ トレーニングデータの設定では、MLモデルがトレーニングするデータ = 列を選択し、[次へ]を押下(今回は「TripDistance (走行距離)」を選択)
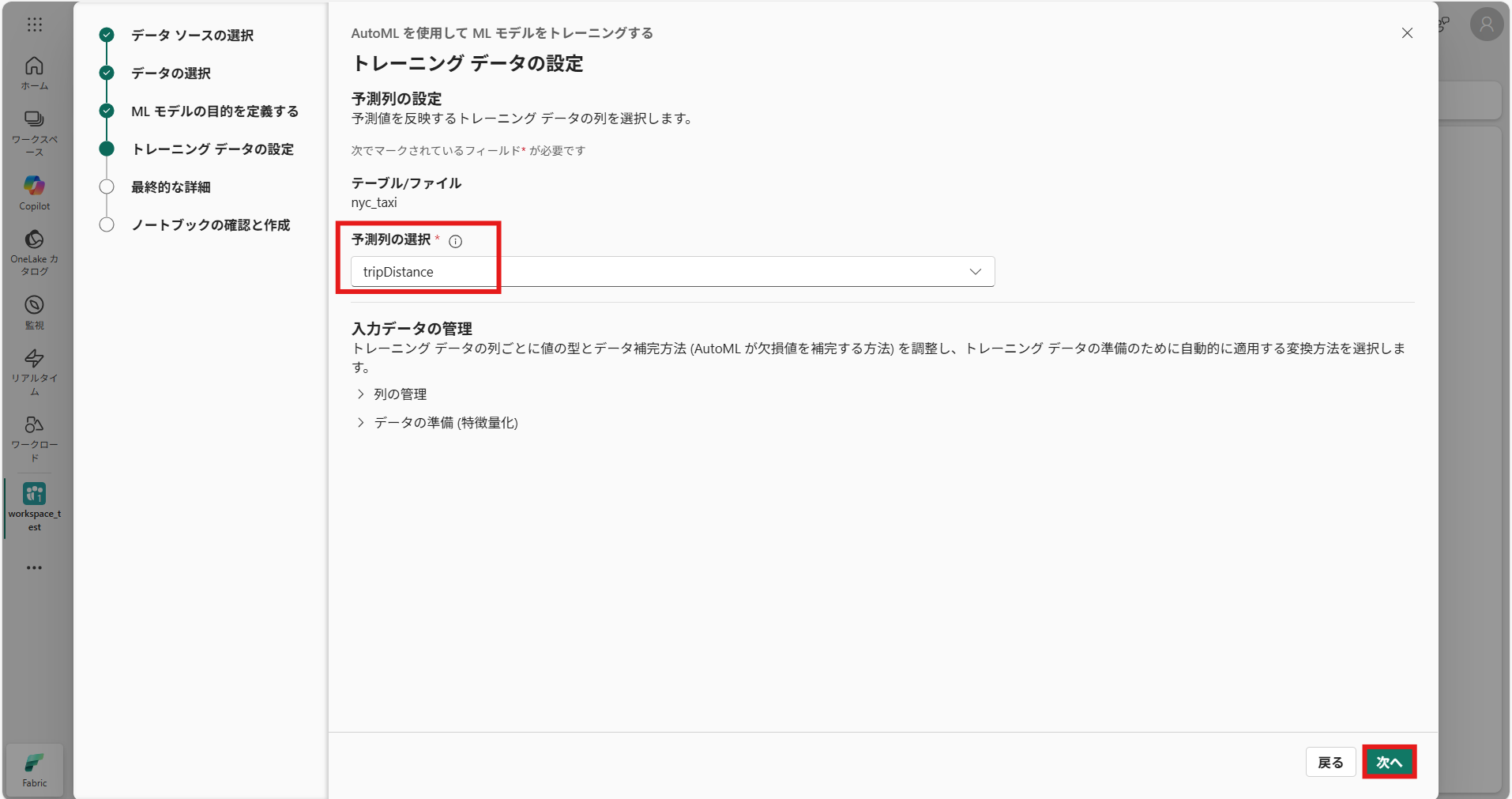
⑧ 最終的な詳細を設定する(今回はノータッチでOK)
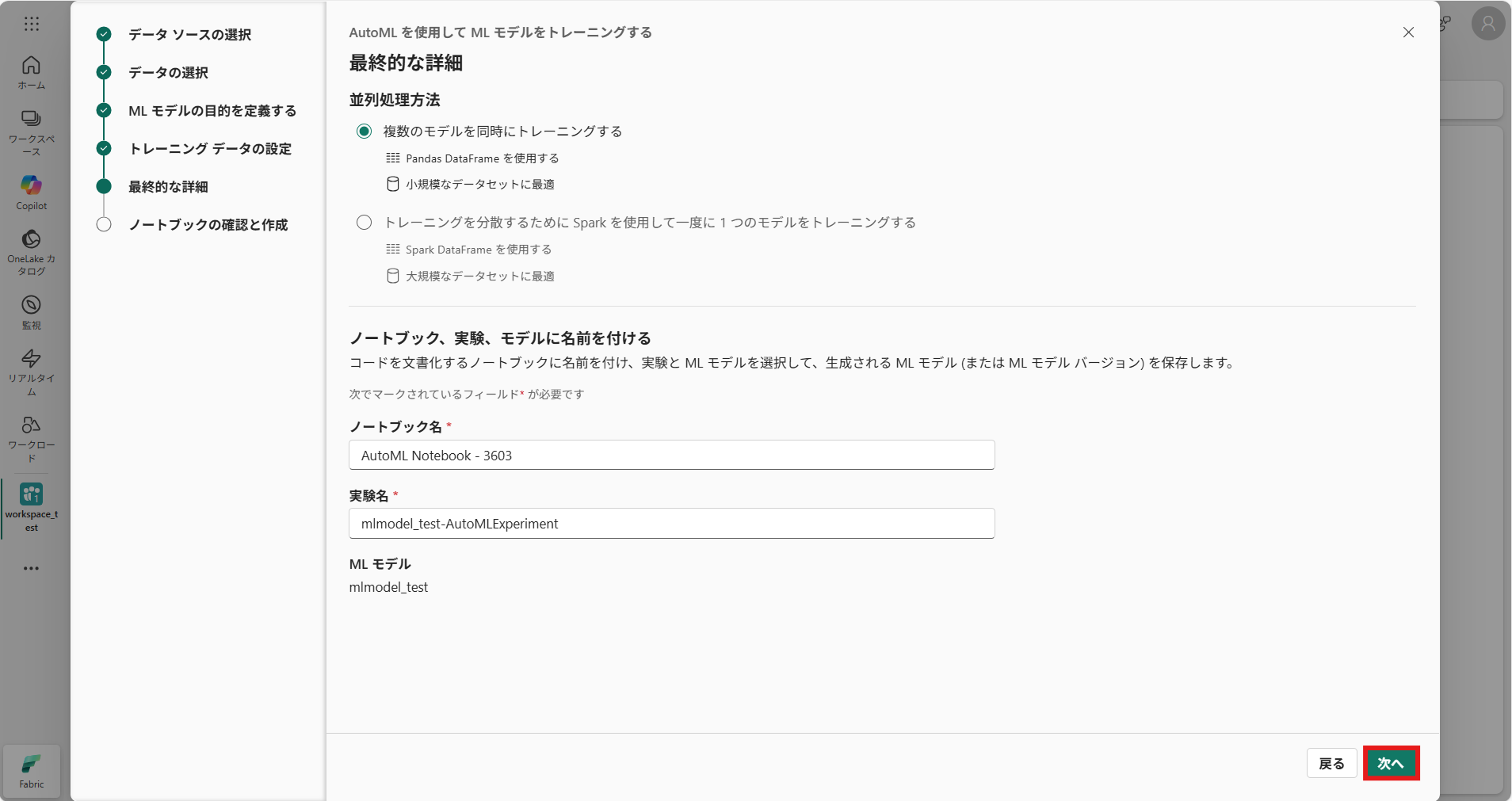
⑨ [作成] を押下すると、ノートブックが作成されるので、[実行] > [すべて実行]を押下して機械学習を開始する
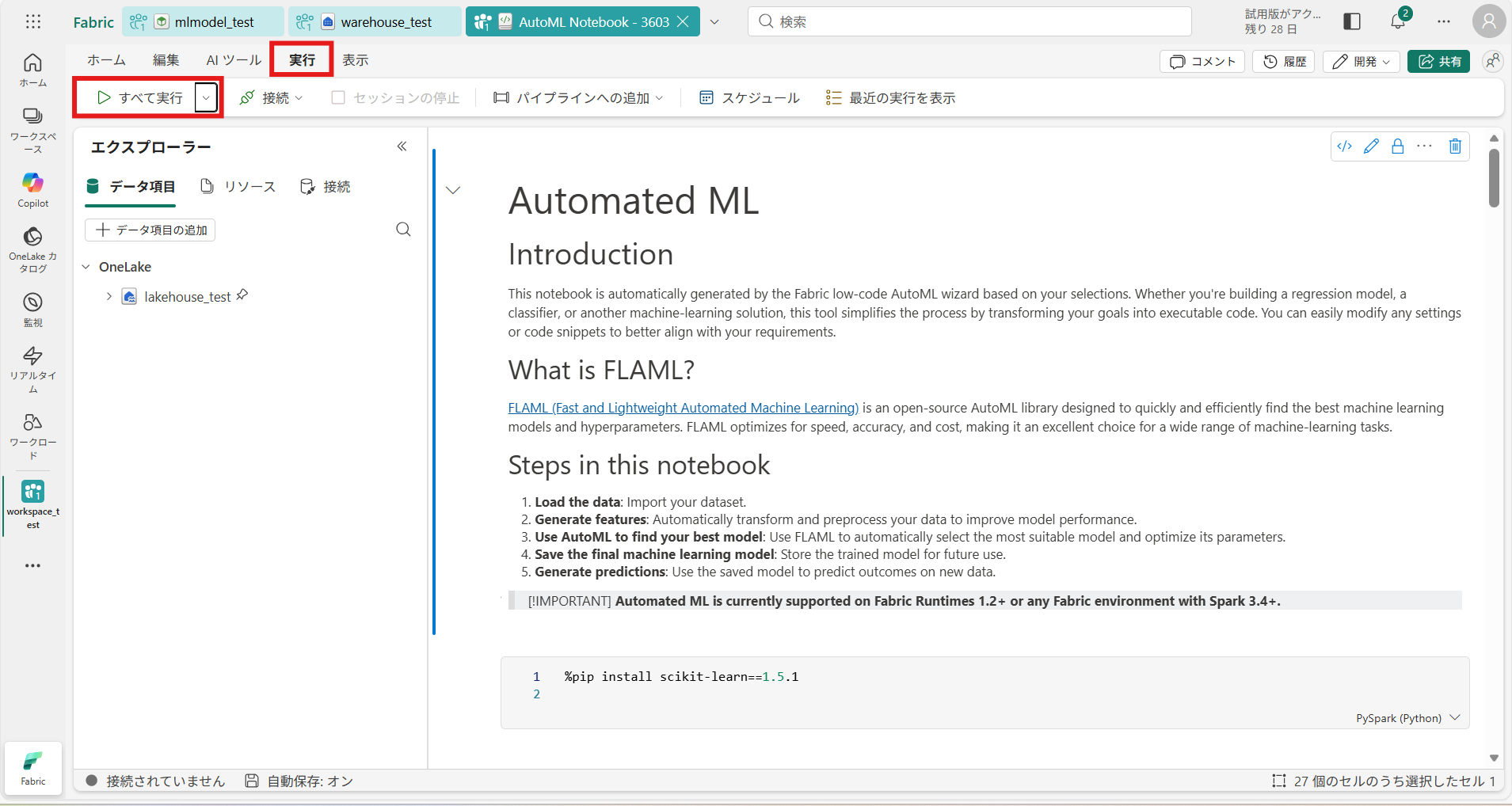
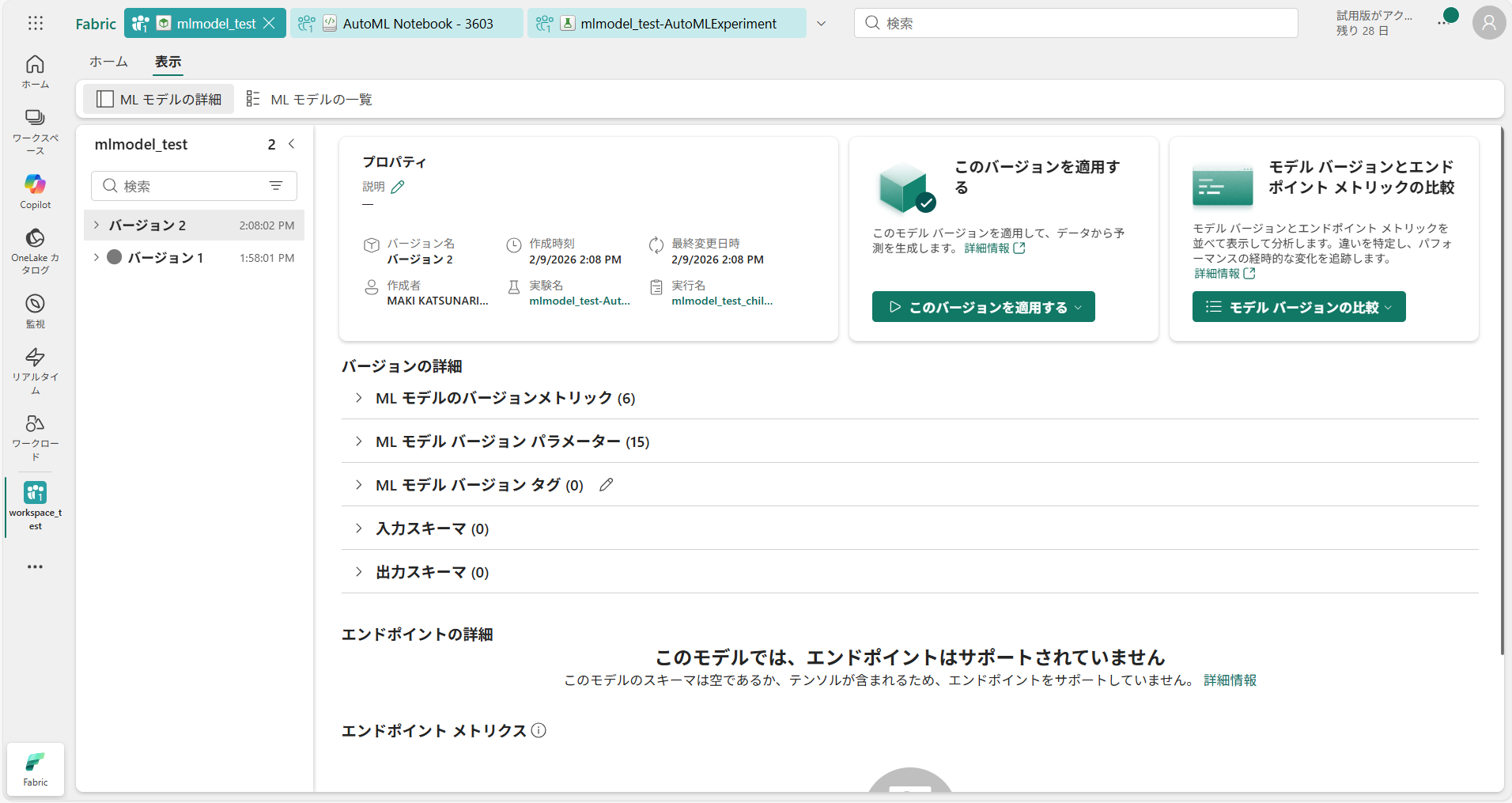
⑩ 実行後、ワークスペースに “実験(Experiment)” が作成される さらに [MLモデルとして保存] を押下
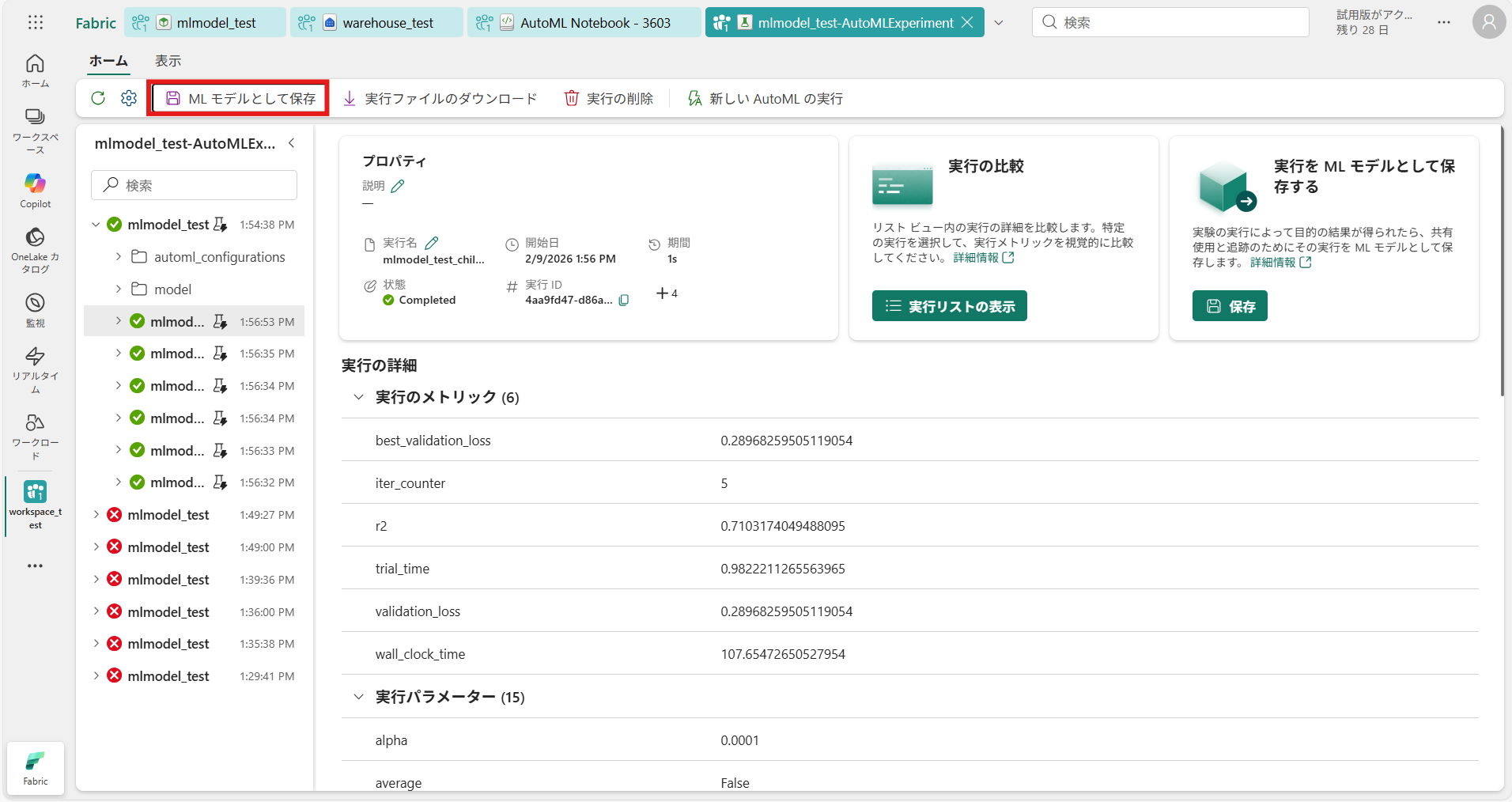
⑪ 既存のモデルを選択し、先ほどの「mlmodel_test」を選択して[保存]を押下
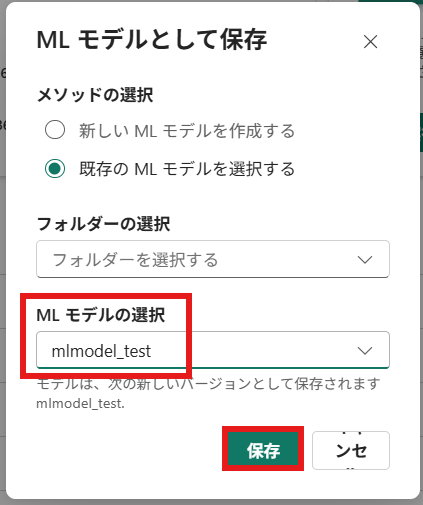
⑫ MLモデル[mlmodel_test]に学習内容が反映される
-
バイナリ分類:2つのクラスのどちらかを判定するタスク
以上でモデルの学習は完了です。 このモデルを使用することで、データから予測や分類・判定ができるようになります。
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事



この著者の保持資格