Microsoft Fabricとは? ~基礎からわかる統合データ基盤の全体像~

目次
Microsoft Fabricとは
Microsoft Fabricとは、データ分析に必要な機能を一つに統合した
”エンドツーエンドのSaaS型データプラットフォーム”です。
データの収集から保存、加工、分析、可視化までを一貫して行うことができ、
分断されがちだったデータ活用プロセスをシンプルにまとめることができます。
複数のツールや基盤を個別に管理する必要がなく、Microsoftが提供する
クラウド基盤上で、データ活用に関わるすべての作業を完結させることが可能です。
【Microsoft公式ドキュメント】
・Microsoft Fabric 基礎ドキュメント – Microsoft Fabric | Microsoft Learn
Microsoft Fabricの主なメリット
-
データ管理の一元化
Microsoft Fabricでは、すべてのデータが統合ストレージ基盤である OneLake に集約されます。
これにより、部門やシステムごとにデータが分散することなく、 単一のデータ基盤として一元管理できます。
また、データの重複やサイロ化を防ぎ、ガバナンスやセキュリティ管理も容易になります。 -
ワークロードの合理化
データの収集・保存・加工・分析・可視化といったすべてのワークロードを、 単一のリソースプール内で一貫して処理できます。
従来のようにツール間の連携やデータ移動を意識する必要がなく、開発・運用の複雑さを大幅に削減できます。 -
迅速な意思決定
AIツールや Power BI とのシームレスな連携により、 リアルタイム分析や高度なデータ可視化が可能です。
最新のデータをもとにビジネスの状況を即座に把握できるため、 より迅速かつ的確な意思決定を支援します。 -
高いスケーラビリティ
データ量や利用ユーザー数の増減に応じて柔軟にスケールでき、 パフォーマンスを損なうことなく利用を拡張できます。
スタートアップから大企業まで、あらゆる規模・フェーズの開発やデータ活用に対応可能です。 -
コスト管理のしやすさ
Microsoft Fabricは、Microsoftが提供するクラウド基盤上で完結する 定額料金モデルを採用しています。
そのため、コストの見通しが立てやすく、無駄な支出を抑えながら 効率的な運用とコスト削減を実現できます。
Microsoft Fabricの基本構造
Microsoft Fabricは、共通のプラットフォーム層(アーキテクチャ)と、
用途別に最適化されたワークロード(コンポーネント)で構成されています。
この2層構造により、データの一貫性・拡張性・運用効率を高いレベルで両立しています。

アーキテクチャ(プラットフォーム層)
アーキテクチャは、Microsoft Fabricのすべての機能で共通して利用される基盤部分です。
データ管理、セキュリティ、AI支援など、Fabric全体を支える役割を担っています。
OneLake
OneLakeは、Microsoft Fabric全体のワークロードを支える統合ストレージ基盤です。
- すべてのデータを OneLake に集約することで、一元管理を実現
- データの重複やサイロ化を防止
- 各ワークロードが同じデータを参照でき、データ連携を意識する必要がない
Fabric における OneLake は、データ活用の中心的な存在です。
Copilot
Copilotは、Microsoft Fabricの各ワークロードに直接組み込まれたAI支援機能です。
- データ分析やクエリ作成を自然言語でサポート
- 分析作業の効率化と属人化の解消に貢献
- データ活用のハードルを下げ、非エンジニアでも扱いやすい環境を実現
Governance(ガバナンス)
Fabricでは、データガバナンス機能が標準で組み込まれています。
- 権限管理
- データのラベル付け
- 操作ログや監査の自動取得
これらを自動化することで、データの信頼性・セキュリティ・コンプライアンスを継続的に維持できます。
コンポーネント(ワークロード)
コンポーネントは、特定の役割や用途に特化したワークロード群です。
全てのコンポーネントがOneLakeを中心に連携し、シームレスなデータ活用を実現します。
Data Factory
Data Factoryは、データの収集・移行・変換を担うETL/ELTワークロードです。
- 分散したデータソースから効率的にデータを取り込み、変換
- 200種類以上のネイティブコネクタを提供
- マルチクラウドやオンプレミス環境にも対応
- 大量データを一元的に取得・加工可能
主要な要素:データフロー(Dataflow Gen2)、パイプライン
【Microsoftの公式ドキュメント】
・What is Data Factory – Microsoft Fabric | Microsoft Learn
Data Science(Analytics)
Data Scienceは、機械学習や高度な分析を行うためのワークロードです。
- 機械学習モデルの構築・デプロイ・運用が可能
- 分析結果や実験履歴を保存し、再利用できる
- データサイエンスのプロセスを効率的に管理
主要な要素:MLモデル
【Microsoftの公式ドキュメント】
・Explore Data Science in Microsoft Fabric – Microsoft Fabric | Microsoft Learn
Databases
Databasesは、開発者向けのトランザクション処理や運用データベースを提供します。
- 高いSQLパフォーマンスとスケーラビリティ
- ミラーリング機能により、既存システムのデータをOneLakeへ統合可能
- 分析用途と運用用途をシームレスに連携
主要な要素:SQL database、Cosmos DB database
【Microsoftの公式ドキュメント】
・SQL database Overview – Microsoft Fabric | Microsoft Learn
・Cosmos DB Database – Microsoft Fabric | Microsoft Learn
Real-Time Intelligence
Real-Time Intelligenceは、リアルタイムデータ分析に特化したワークロードです。
- データ発生と同時に分析・可視化・アクション抽出が可能
- アプリケーションログやWebのクリックストリーム分析に最適
- 即時性が求められるユースケースに対応
主要な要素:イベントハウス、Eventstream、アクティベーター、リアルタイムダッシュボード
【Microsoftの公式ドキュメント】
・What Is Real-Time Intelligence in Microsoft Fabric? – Microsoft Fabric | Microsoft Learn
IQ(プレビュー版)
IQは、データ・モデル・システム間のビジネスセマンティクスを統合する機能です。
※現在はプレビュー版として提供されています。
- データの意味や文脈を共通化
- 分析結果の解釈や再利用性を向上
主要な要素:Graph model、Ontology、データエージェント
【Microsoftの公式ドキュメント】
・What is Fabric IQ (preview)? – Microsoft Fabric | Microsoft Learn
Power BI
Power BIは、Microsoftを代表するビジネス分析・可視化プラットフォームです。
- データをリアルタイムに可視化
- 対話型ダッシュボードやグラフの作成
- 分析結果の共有・コラボレーションが可能
Microsoft Fabricの中核的なアウトプット手段として位置付けられています。
主要な要素:レポート、ダッシュボード、セマンティックモデル
【Microsoftの公式ドキュメント】
・What is Power BI? Overview of Components and Benefits – Power BI | Microsoft Learn
Data Engineering
Data Engineeringは、大規模データ処理基盤を構築・運用するためのワークロードです。
- Apache Sparkを利用した分散データ処理
- ノートブックによるデータ変換ジョブの記述・スケジューリング
- 大量データを最適な状態で管理・分析可能
主要な要素:レイクハウス、Notebook
【Microsoftの公式ドキュメント】
・What is a lakehouse? – Microsoft Fabric | Microsoft Learn
Data Warehouse
Data Warehouseは、分析・意思決定のためのデータ蓄積基盤です。
- 複数システムから収集したデータを統合・変換・管理
- 高速なクエリ処理で分析を支援
- オープンフォーマットのため外部ツールからも活用可能
主要な要素:ウェアハウス、Notebook
【Microsoftの公式ドキュメント】
・What is Fabric Data Warehouse? – Microsoft Fabric | Microsoft Learn
Industry Solutions
Industry Solutionsは、業界固有の課題に対応したデータソリューションです。
- 業界特化のデータモデルや分析機能を提供
- データ管理から分析、意思決定までを包括的に支援
- 短期間での導入・価値創出を実現
主要な要素:持続可能性ソリューション、小売ソリューション、医療データソリューション
【Microsoftの公式ドキュメント】
・Industry Solutions in Microsoft Fabric | Microsoft Learn
Microsoft Fabricを試用版(無料)で利用する方法
Microsoft Fabricを実際に操作してみたい場合、以下の手順で試用版を利用することができます。
前提条件:
- Microsoft Entra ID テナントが存在する
- 上記テナント内に、組織アカウント(ユーザー)が存在する
※個人アカウントではMicrosoft Fabricを利用できないので注意
-
Fabricポータルにアクセス
以下にアクセスし、組織アカウントでサインインします。
・https://app.fabric.microsoft.com -
画面右上の プロフィールアイコン をクリック
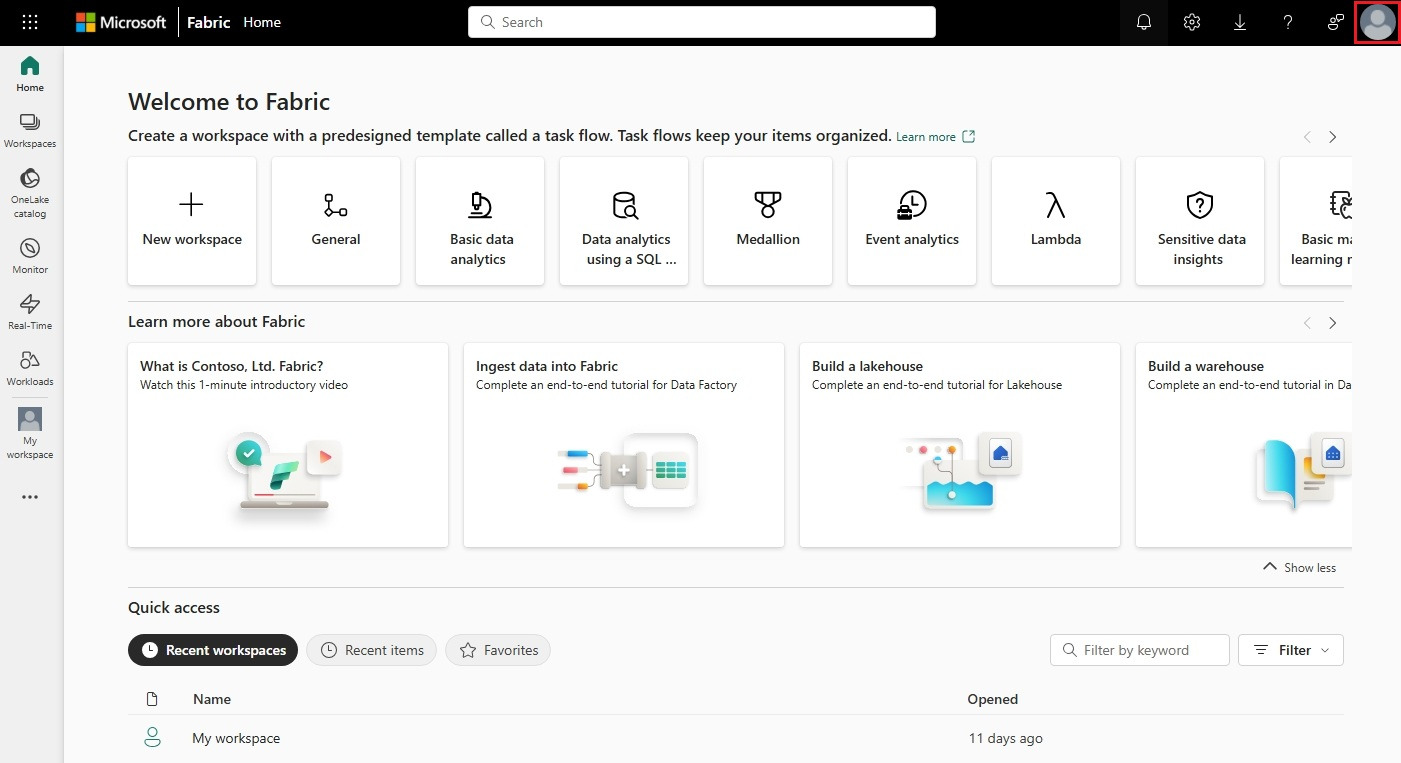
-
「Free trial(試用版を開始)」 を選択

-
再度プロフィールアイコンを開き、試用版が有効になった事を確認する
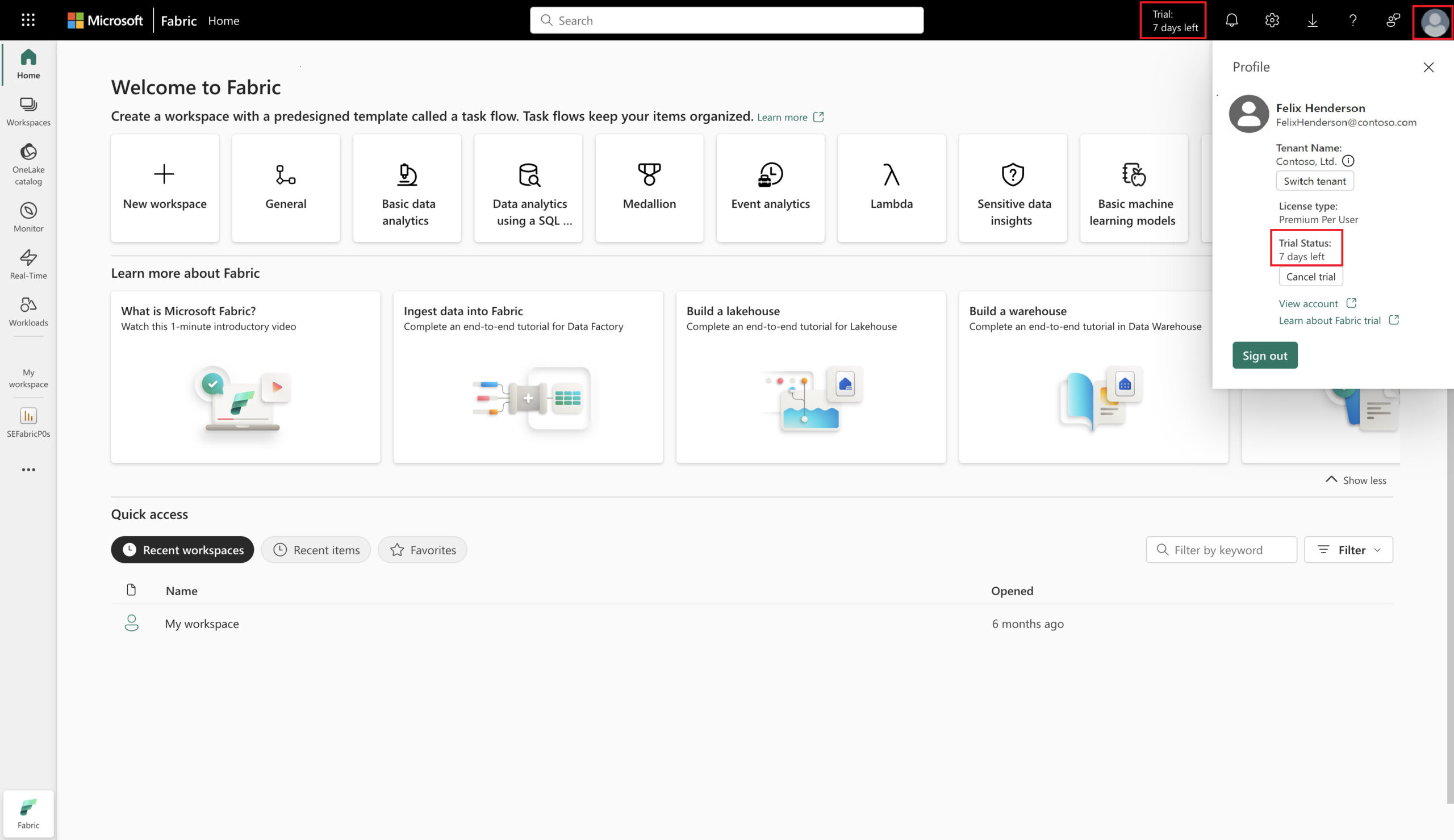
試用版では、Fabricが提供する機能のほぼ全てを60日間無料で使用することができます。
また、Fabricポータルで作成したワークスペースにユーザーやグループを追加することで、ワークスペース内のメンバーが試用版を利用できるようになります。
【Microsoftの公式ドキュメント】
・Fabric trial capacity – Microsoft Fabric | Microsoft Learn
OneLakeについて
Microsoft Fabricでは、「データレイク」が全てのワークロードの共通基盤として位置づけられています。
この中核となるデータレイクがOneLake(ワンレイク)です。
【Microsoftの公式ドキュメント】
・OneLake、データ用OneDrive – Microsoft Fabric |Microsoft Learn
OneLakeとはなにか?
OneLakeはMicrosoft Fabricにネイティブに組み込まれたデータレイクで、
組織内のあらゆるデータを単一のストアとして一元管理することを目的としています。
従来のようにワークロードごとにストレージを分けて管理する必要はなく、Fabric上のすべての分析体験が同じデータ基盤を共有します。
OneLakeの基盤技術
OneLakeは Azure Data Lake Storage(ADLS)Gen2 を基盤として構築されています。
これにより、エンタープライズ用途に求められる以下のような特性を備えています。
- 高いスケーラビリティ
- セキュリティとガバナンス
- 階層型名前空間による効率的なデータ管理
OneLakeはテナント単位で提供されるデータストアであり、テナント全体を横断する単一のデータレイクとして機能します。
OneLakeのファイルシステム
OneLakeの大きな特徴の一つが、ユーザー、リージョン、クラウドをまたいだ単一のファイルシステム名前空間を持つ点です。
- データはテナント全体で論理的に一つのレイクとして扱われる
- 地理的な配置(リージョン)やワークロードの違いを意識せずにデータへアクセス可能
- 組織内のデータサイロを解消しやすい
テナント内には複数のワークスペースを作成でき、それぞれのワークスペースがOneLake上の論理的な領域としてデータを管理します。
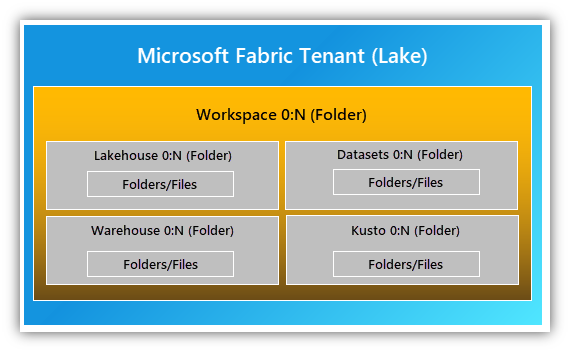
OneLakeの階層構造
OneLakeは階層的に設計されており、概念的には以下のような構造を持ちます。
テナント
└ ワークスペース
└ データ(Lakehouse、Warehouse、Files など)
この階層構造により、
組織全体 → 部門 → プロジェクト
といった形で、スコープを明確にしながらデータを整理・管理することが可能になります。
OneLakeの階層的な設計は以下のイメージのようになります。
Microsoft Fabricにおけるデータの扱い方
Microsoft Fabricで外部データを扱う方法には、大きく分けて以下の3パターンが存在します。
-
コピー(完全複製)
“コピー(Copy)”とは、外部または内部のデータを OneLake 上に物理的に取り込み、実体として保持する方式です。
データは元データソース(データベース、ファイルストレージなど)とは物理的に切り離され、 Fabric 側で独立したデータ資産として管理されます。
コピーされたデータは OneLake 内に Delta / Parquet 形式で保存され、 Spark、SQL、Direct Lake、Power BI、Data Science などの全ての Fabric ワークロードからネイティブに利用可能となります。
単なる参照ではなく Fabric の計算基盤に最適化された形でデータを再配置するアプローチであり、 本格的な ML(機械学習)や高度な分析処理の基盤として不可欠となります。
Microsoft Fabricではコピーを通常、Data Pipeline、Dataflow Gen2、SQLなどから行います。【Microsoftの公式ドキュメント】
・How to copy data using copy activity – Microsoft Fabric | Microsoft Learn -
ショートカット(仮想化)
Microsoft Fabric の OneLake には、“ショートカット(Shortcut)” という仕組みがあります。
これは OneLake 内にポインタ(シンボリックリンクのようなもの)を作成し、 実体は別の場所にあるデータをOneLake内に存在するかのように扱う機能です。
ショートカットを利用することで Azure Data Lake Storage Gen2 や Amazon S3、 あるいは同一テナント内の別の OneLake 領域にあるデータを物理的にコピーすることなく Fabric 上から参照・利用できます。
Spark、SQL、KQL、Power BI(Direct Lake)といった Fabric の各分析エンジンは、 これらのデータを透過的に読み取ることが可能です。
一方で注意点として、既存のデータベースをそのまま Fabric の計算基盤(Spark / SQL / Direct Lake)に 直接ぶら下げて利用する機能は現時点では提供されていません。
Fabric の計算エンジンは OneLake 上の Delta / Parquet 形式のデータを前提としており、 外部データベースを直接クエリエンジン下で処理する構成はサポートされていません。
また、機械学習モデル(MLモデル)の学習や高度な分析処理を行う場合には、 パフォーマンスや再現性、分散処理の観点から、データの実体が OneLake 上に存在することが前提となります。
そのため、ショートカットで参照しているデータであっても、 ML や高度分析用途では Delta テーブルとしてコピー・保持する必要があります。
このように OneLake のショートカットは、データ統合や参照レイヤーとしては強力である一方、 演算・学習用途では物理データが必要という明確な役割分担を理解することが重要です。【Microsoftの公式ドキュメント】
・Unify data sources with OneLake shortcuts – Microsoft Fabric | Microsoft Learn -
ミラーリング(準リアルタイム複製)
“ミラーリング(Mirroring)”は、既存のデータベースや外部データソースから OneLake にデータとメタデータを継続複製(Near Real-Time)し、 分析に最適化されたDelta 形式で常に最新化してくれる Fabric の機能です。
データソースに接続し、DB 全体または特定のテーブルを選ぶと、 OneLake に Delta テーブルとして自動複製が走り、以後は継続同期されるようになります。
複製されたデータは Fabric のすべてのワークロード(Spark、SQL、Power BI、Data Science など)からそのまま利用できます。【Microsoftの公式ドキュメント】
・Mirroring – Microsoft Fabric | Microsoft Learn
以上が Microsoft Fabric の概要になります。
より具体的な機能や操作手順についてもまとめているので、気になる方はこちらを参照してみてください。
・Microsoft Fabricの操作ガイド ~基本操作とワークフロー解説~
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事


この著者の保持資格