Azure SQL DataWarehouse④ データ分散

IM事業部の 田村 です。
今回はAzure SQLDataWarehouseのテーブルのデータ分散方法の種類についてご紹介します。
データ分散とは
SQLDataWarehouseでは下の図のように内部でテーブルのデータを60個のストレージに分散して保持します。
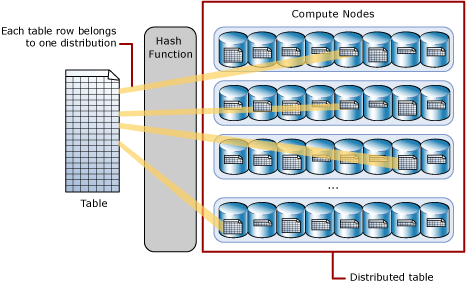
このデータ分散方法をCREATE TABLE時に以下の3種類から指定することができます。
1.ハッシュ分散テーブル
2.ラウンドロビン分散テーブル
3.レプリケートテーブル
次項から各分散方法の指定方法と、どういったケースに使用すべきなのかを見ていきましょう。
1.ハッシュ分散テーブル
ハッシュ分散テーブルは指定されたキーによってデータを60個のストレージに分散します。
SQLDataWarehouseの基本的な分散方法と言え、大容量のデータが格納されるテーブルに使用するのが妥当と言えます。
ここでのポイントはなるべく均等に分散されるようなキー(カラム)を指定することです。
どういったカラムが適当かといいますと、基本的には以下の条件に該当するキーを指定するとよいでしょう。
・1000以上のバリエーションがある
・結合キーに指定される
・GROUP BY句に指定される
・WHERE句には指定されない
上記の条件に合致するようなキーを指定することにより、クエリ発行時のSQLDateWarehouse内部でのデータの移動が少なくなり、かつ最適な並列処理が実行されるようになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[SAMPLE_TABLE01] ( [SAMPLE_01] CHAR(2) NOT NULL, [SAMPLE_02] NVARCHAR(10) NOT NULL, [SAMPLE_03] CHAR(5) NOT NULL ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([SAMPLE_03]) /*分散方法をHASHに、キーにSAMPLE_03列を指定*/ ); |
2.ラウンドロビン分散テーブル
ラウンドロビン分散テーブルはテーブルのデータを60個のストレージにランダムかつ均等に分散されます。
ハッシュ分散テーブルのキーに指定するようなカラムがないような時に使用するとよいでしょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[SAMPLE_TABLE01] ( [SAMPLE_01] CHAR(2) NOT NULL, [SAMPLE_02] NVARCHAR(10) NOT NULL, [SAMPLE_03] CHAR(5) NOT NULL ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN /*分散方法をROUND_ROBINに指定*/ ); |
3.レプリケートテーブル
レプリケートテーブルは最近登場したもので、サイズが小さいテーブルに対して最適です。
この種類のテーブルは例外として、ストレージ分散されたデータを読み込むのではなく、コンピュートノードにテーブルのコピーを保持します。
これにより、小規模のテーブルに対しては高速な読込が可能となります。
実はラウンドロビンテーブルはほとんどの場合、レプリケートテーブルに変換した方がより高速になると言われています。(ラウンドロビンの存在意義とは・・・。)
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[SAMPLE_TABLE01] ( [SAMPLE_01] CHAR(2) NOT NULL, [SAMPLE_02] NVARCHAR(10) NOT NULL, [SAMPLE_03] CHAR(5) NOT NULL ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = REPLICATE /*分散方法をREPLICATEに指定*/ ); |
実際に小規模テーブルというのはどれくらいのサイズかといいますと、2GB以下と言われています。
以下のコマンドで実際のテーブルサイズが調べられるので、どのテーブルがレプリケートに最適なのか調べてみるとよいでしょう。
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事




この著者の保持資格