社内ナレッジを“使える資産”に。PDFの構造化により、RAGの精度課題を業務成果に変える方法
2026.04.14
目次
はじめに
MS開発部の松坂です。生成AIの業務活用が進む一方で、「回答が惜しい」「文脈が抜ける」「図表を正しく認識しない」といったRAGの精度課題に悩む企業は少なくありません。特にPDF中心の情報資産では、単純な文字抽出だけでは意味構造が崩れ、正確な回答が難しくなります。
本記事では、Azure AI Searchのカスタムスキルを使用して、指定URL経由でPDFを構造化し、生成AI 精度向上につなげた取り組みを、わかりやすく解説します。
なぜ通常のPDF取り込みではRAG精度に限界があるのか
導入前の課題(実務で起きていたこと)
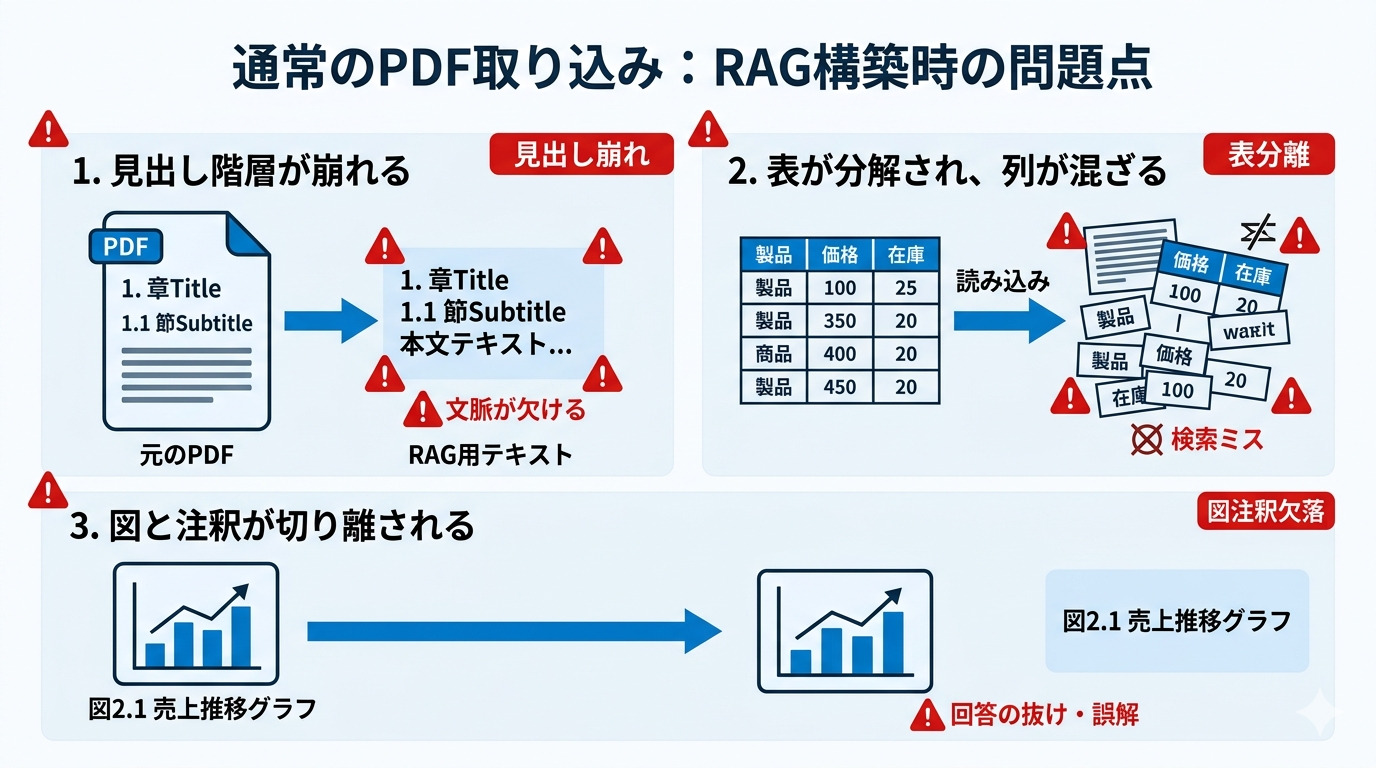
多くのRAG実装では、PDFを「テキストの塊」として取り込みます。すると、次の問題が起こります。- 表題と本文の関係が失われ、回答が論点ずれする
- 見出し階層が崩れ、前提条件を読み落とす
- 図・表の注釈が分離され、数値の意味を誤解する
- ページまたぎで文脈が途切れ、回答の抜け漏れが増える
 結果として、問い合わせ対応では「再確認」が増え、社内検索では「見つかるが使えない」状態になり、現場の意思決定が遅れます。
結果として、問い合わせ対応では「再確認」が増え、社内検索では「見つかるが使えない」状態になり、現場の意思決定が遅れます。
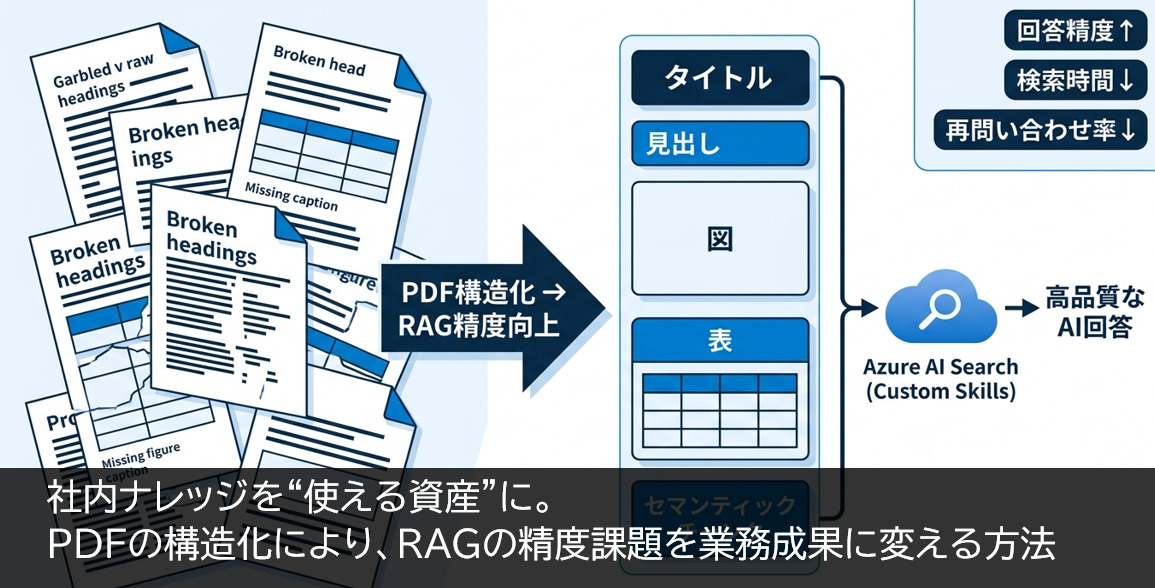
Azure AI Searchを活用したPDF構造化の独自アプローチで生成AIの精度を向上
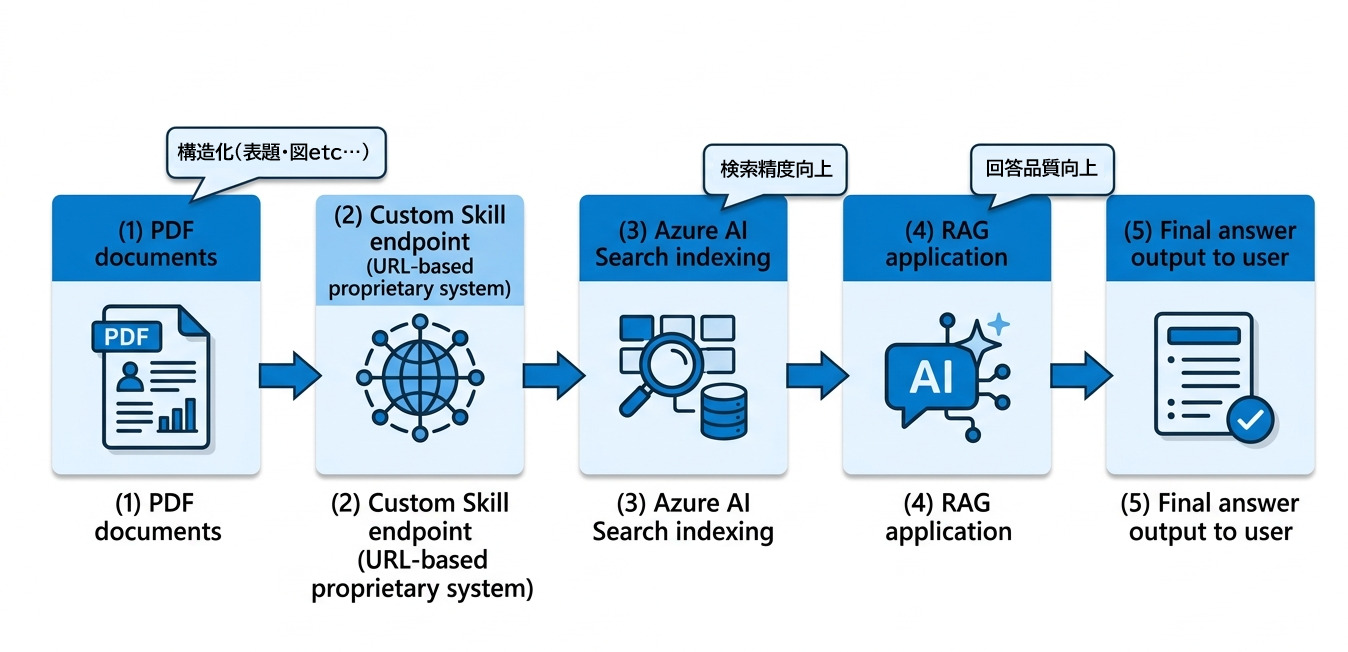
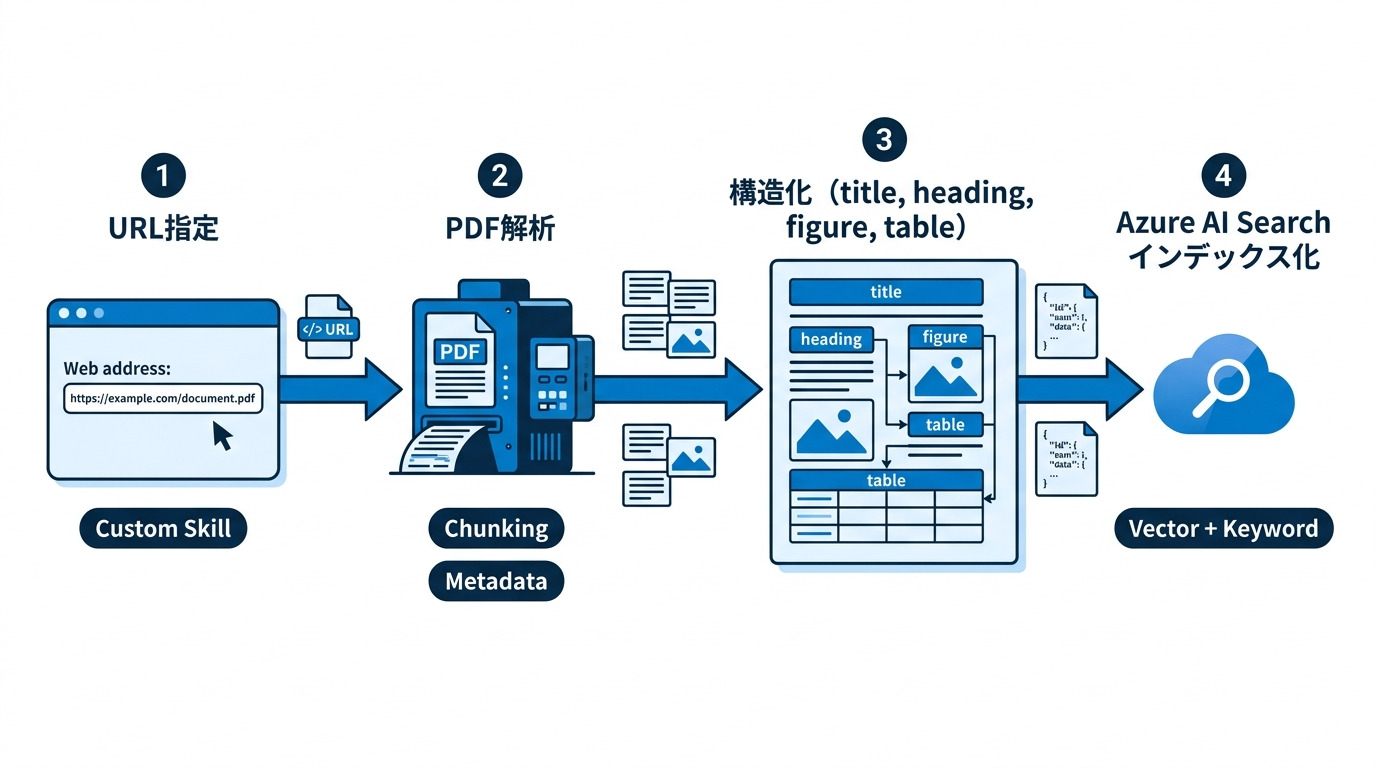
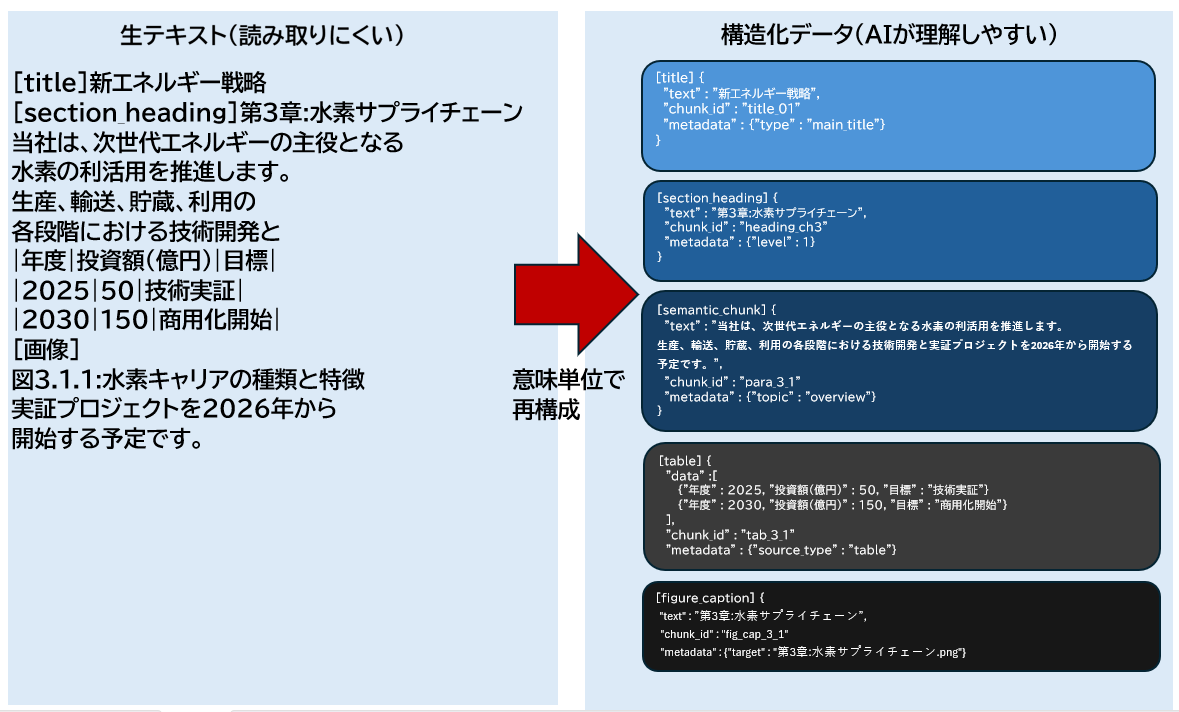
今回の取り組みでは、Azure AI Searchのインデクシング時にカスタムスキルを組み込み、自作システムのURLを指定してPDFを解析する仕組みを構築しました。ポイントは「文字を抜く」のではなく、「意味を保つ」ことです。
実装の要点
- PDFをURL経由で取得し、解析サービスに連携
- 表題・見出し・本文・図・表を識別
- 各要素を関連づけたまま検索用データへ変換
- RAGで参照しやすい粒度(チャンク)に最適化
非エンジニア向けの比喩で言うと
従来の取り込みは、ラベルのない段ボールを倉庫に積む状態です。中身はあるのに、探すたびに開封が必要です。PDF構造化は、「棚番号・カテゴリ・取扱説明付き」で保管する状態。必要な情報に最短で到達でき、取り違えも減ります。RAGの品質は、この「保管方法」で大きく変わります。
導入前と導入後の変化
対比で見る効果
導入前の課題- 回答の根拠が曖昧で、現場が再確認に時間を要する
- 図表を含む問い合わせで誤解が生じる
- PoCでは機能するが、本番運用で品質が安定しない
- 回答の文脈整合性が向上し、問い合わせ一次回答の品質が改善
- 社内検索で必要情報への到達時間が短縮
- ナレッジ再利用が進み、部門間で回答品質を平準化
- 現場工数の削減、意思決定の迅速化、顧客対応品質向上を同時に実現

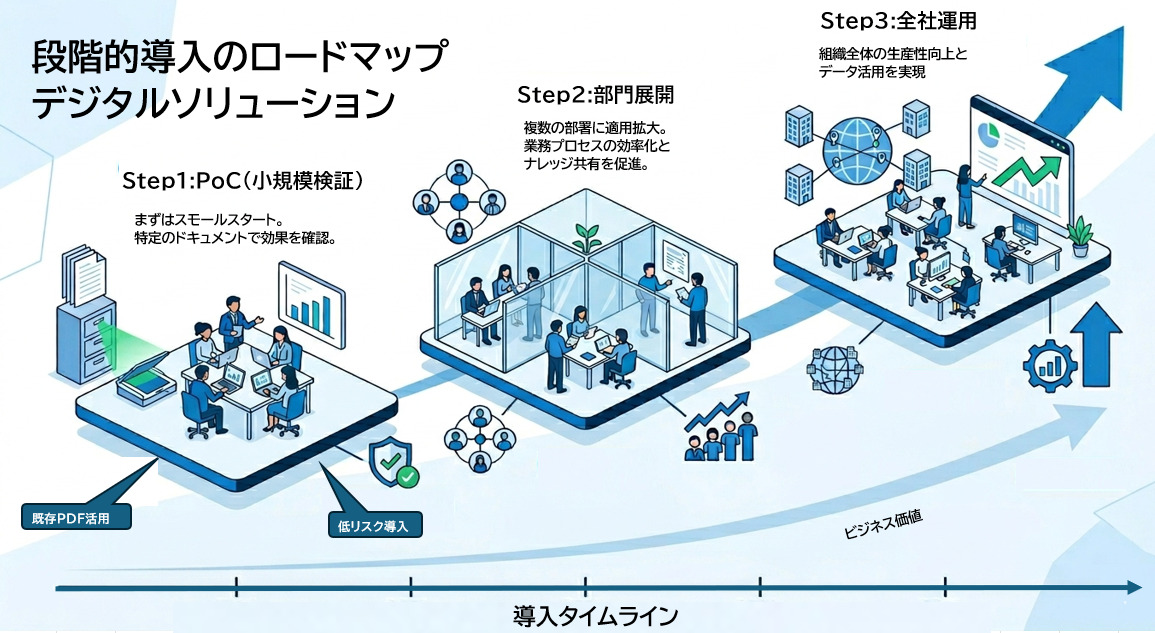
既存資産を活かし、段階的に拡張できる
既存ドキュメントを活用
新規で文書を作り直す必要はありません。既存PDFを対象に、優先度の高い業務領域から段階的に適用できます。小さく始める段階導入
まずは特定部門・特定文書群でPoCを実施し、効果指標(回答正確性、検索時間、再問い合わせ率)を確認。成果が見えた範囲から横展開できます。セキュリティと運用の観点
- アクセス制御に合わせたインデックス設計
- 機密区分に応じた処理経路の分離
- 更新頻度に応じた再インデックス運用
- 監査ログを意識したトレーサビリティ確保
まとめ
Azure AI Searchのカスタムスキルを活用したPDF構造化は、RAGの弱点である文脈欠落を補い、生成AIの精度向上を実務成果に変える現実的なアプローチです。重要なのは、モデルの性能競争より先に、AIが読み取りやすい情報構造を整えること。
「PoCはできたが本番品質が不安」「PDF資産を活かして短期間で成果を出したい」という企業ほど、効果を実感しやすい領域です。次のステップとして、自社文書を使った簡易診断から始めるのが最短ルートです。
RAGの検索精度改善やAzure AI Search活用をご検討中の方は、
現状診断から設計・実装・運用定着まで、ぜひお気軽にご相談ください。
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事




この著者の保持資格