ベクトル検索は、いま“進化”している~Harrier‑oss‑v1とAzure AI Search を組み合わせた次世代 RAG の実像~
2026.04.22
目次
はじめに
MS開発部の松坂です。2026年現在、ベクトル検索は「やってみた」段階から、「本番で差がつく技術」へと大きく進化しています。
そんな中、Microsoft が公開したオープンソースの埋め込みモデル Harrier‑oss‑v1 は、多言語 MTEB v2 で1位クラスの精度を記録し、Azure AI Search と組み合わせた次世代の RAG 基盤作りに最適なモデルとして注目されています。
本記事では、
- Harrier 0.6B と text‑embedding‑3‑large の比較
- SplitSkill の最適設定
- Azure AI Search との連携フロー
- 27B が現実的に使えるかどうか
1. ベクトル検索は、もう“実験”ではない
2023〜2024年は「ベクトル検索ができた」段階でしたが、2026年に入り、ナレッジ検索や RAG における“本番導入レベル”の精度・安定性が求められるようになっています。
その中で Harrier‑oss‑v1 は、
- 100 言語以上に対応
- Multilingual MTEB v2 で1位クラスのスコア
- 32,768 トークンの長文対応
“第2世代のベクトル検索モデル“ といえる存在です。
2. Harrier 0.6B vs text‑embedding‑3‑large ―次元数・精度・コスト
まず、Harrier 0.6B と OpenAI の text‑embedding‑3‑large を比較してみます。| モデル | 次元数 | MTEB v2 スコア(概略) | コスト / ホスティング |
|---|---|---|---|
| Harrier 0.6B | 1,024 | ≒69.0 | オープンソース、自社/クラウドで自己ホスティング |
| text‑embedding‑3‑large | 最大 3,072 | ≒64.6 | OpenAI API 料金あり |
- Harrier 0.6B は text‑embedding 系より精度が高い指標を出している
- Harrier は自己ホスティング前提のため、API従量課金を抑えつつ運用できます(※別途インフラ費は必要)
特に、
- セキュリティ要件が高い社内ナレッジ
- 各部門別に制御したいオンプレ/ハイブリッド環境
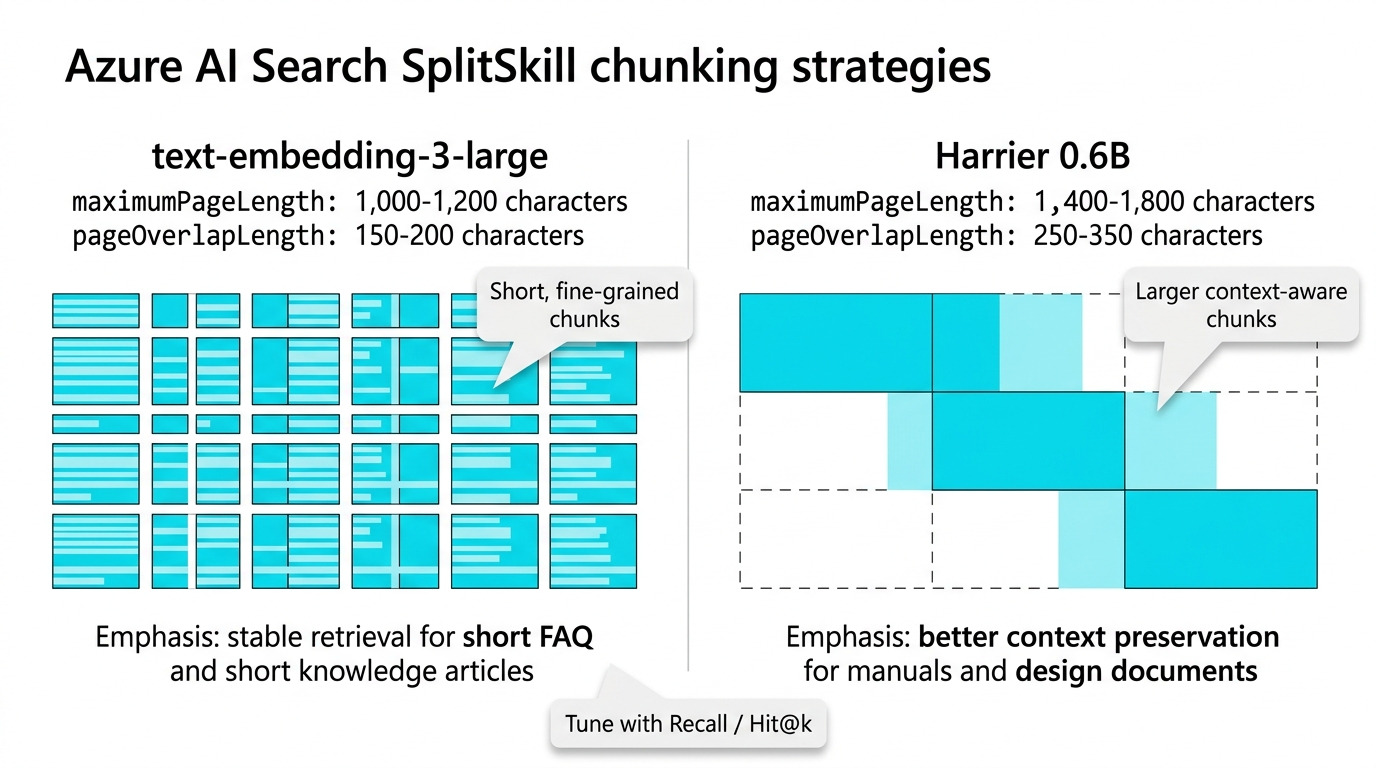
3. SplitSkill の最適値――text‑embedding と Harrier でこんなに変わる
ベクトル検索では、“どこでテキストを切るか”が検索精度に大きく影響します。Azure AI Search で使う
SplitSkill の設定は、モデルによって大きく変わります。text‑embedding‑3‑largeの例
maximumPageLength: 1,000〜1,200 characterspageOverlapLength: 150〜200 characters
特に FAQ や短いナレッジ記事では、このくらいの細かさが返り値の精度を保ちやすいです。
Harrier 0.6B の例(提案設定)
maximumPageLength: 1,400〜1,800 characterspageOverlapLength: 250〜350 characters
- 32k タイムの多言語対応
- 比較的大きな文脈を保ちやすい設計
そのため、インストールマニュアルや設計書など「意味の塊」が重要な文書では、
このくらいの設定を起点として、Recall/Hit@k を観測しながら微調整するのがおすすめです。
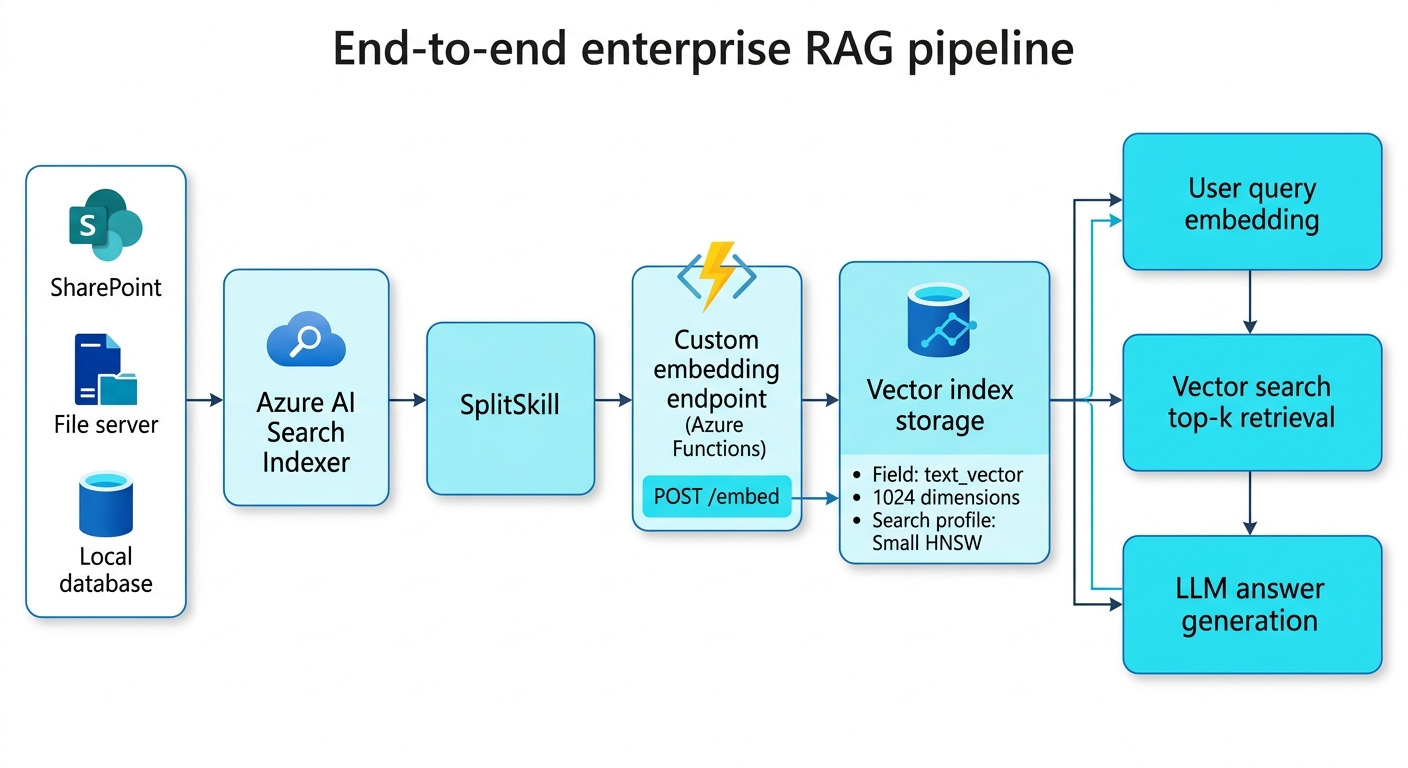
4. Azure AI Search で Harrier 0.6B を動かす実際のフロー
では、実際のシステム構成を見てみましょう。全体フロー
- データソース(SharePoint / ファイルサーバー / ローカル DB など)
- Azure AI Search インデクサー
- SplitSkill(Harrier 向けの 1,400〜1,800 / 300 オーバーラップ)
- Harrier 0.6B を実行する Azure Functions カスタムスキル
- 1,024 次元の
text_vectorをベクトルインデックスに保存 - ユーザ質問 → Harrier で入力テキストをベクトル化 → Azure AI Search で検索 → 上位 k 件を LLM に渡して回答生成
カスタムスキル側には、
- Harrier 0.6B を ONNX / Azure Functions でホストし、
POST /embedを受け付けるエンドポイントを用意
Azure AI Search 側の
text_vector は dimensions: 1024、vectorSearchProfile は HNSW などに設定することで、高精度かつ高速な検索を実現できます。この構成なら、
- Embedding は自社で実行、コストゼロ
- 検索基盤は Azure AI Search で安定運用
5. 27B は“未来の武器”――今の Azure では 0.6B が本命
Harrier には、もっと大きなモデルである 27B 版もあります。- 次元数:5,376
- MTEB v2:≒74.3
- Azure AI Search のベクトルフィールドは、最大 4,096 次元まで
- 5,376 次元をそのまま載せるのは不可
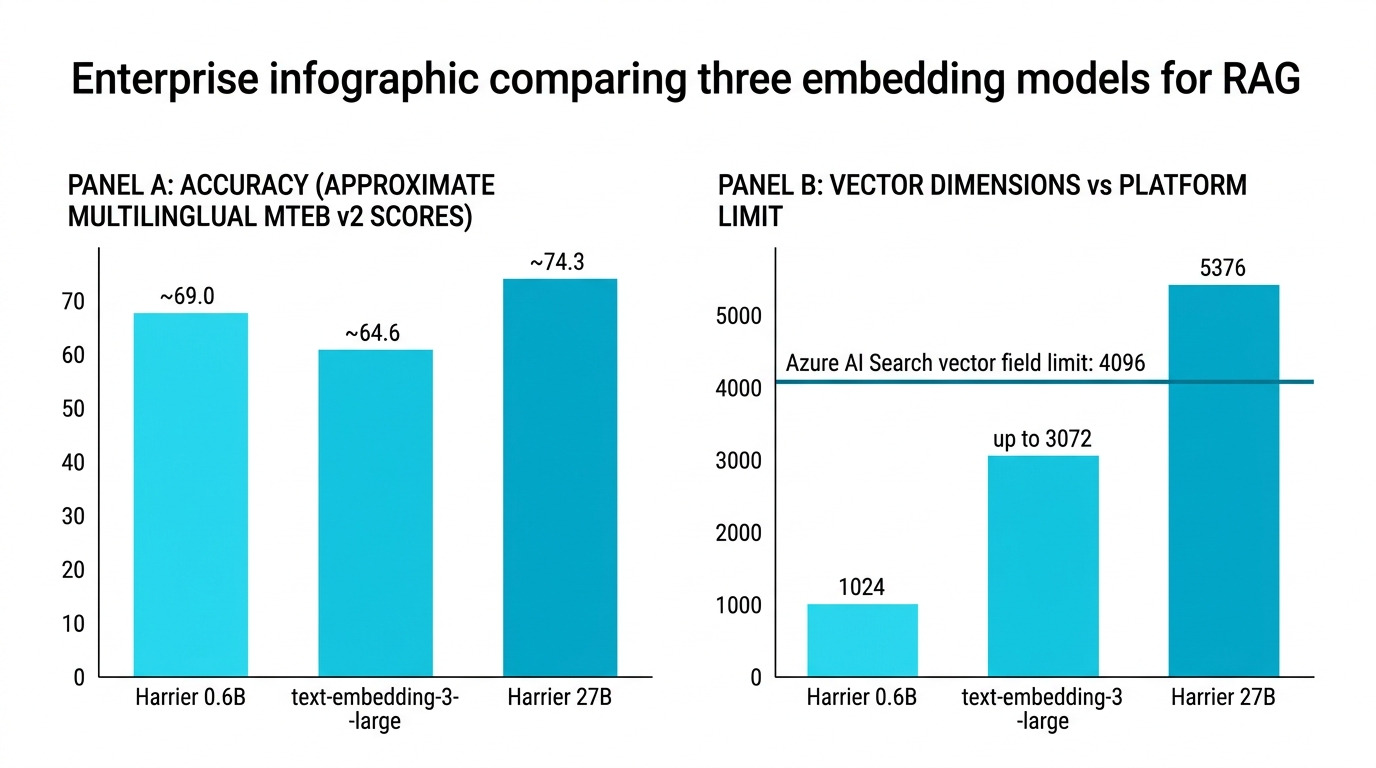
自前で次元削減(PCA など)をすれば、4,096 以下に落とせますが、
精度はそれだけ犠牲になります。
Harrier 側の設計意図は、Matryoshka Representation によって、
3072 / 256 など、既存の長さ切り捨てで自在に使い分けるモデルとして提供されています。
したがって、
- Harrier 27B は“未来の武器”
- Azure AI Search で今、すぐに使えるのは Harrier 0.6B
ただし、将来的に Azure 側の上限が引き上げられた場合、
Harrier 27B のポテンシャルはさらに大きく開かれる可能性があります。
6. 実際の検索精度はどれくらい変わったか
本検証では、同一のPDFドキュメントを対象にチャンク分割を行い、それぞれの埋め込みモデルを用いてベクトルインデックスを構築した上で、QAベースの検索精度を比較しました。評価には、各チャンクから自動生成した約80件のQAペアを用い、質問文をそのままAzure AI Searchのクエリとして投入しました。検索結果として得られた上位5件のチャンクIDと正解チャンクIDを照合し、Hit@5およびMRR@5を算出しています。
結果は以下の通りです。
| モデル | Hit@5 | MRR@5 |
|---|---|---|
| harrier-oss-v1-0.6b | 0.9167 | 0.7071 |
| text-embedding-3-large | 0.7381 | 0.4762 |
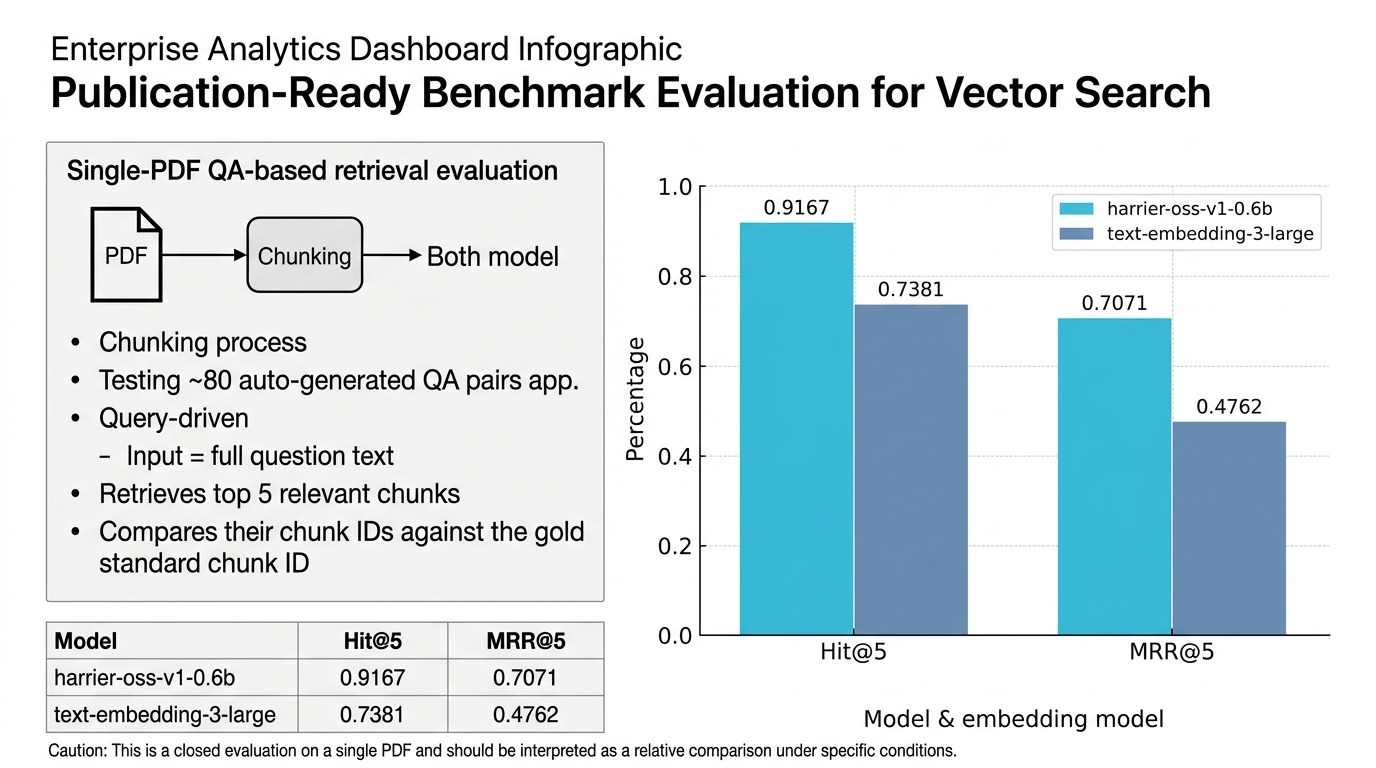 ただし、本結果は単一PDFに対するクローズドなQA生成ベースの評価であり、一般的な検索性能を直接示すものではない点には注意が必要です。チャンク設計やデータ分布、QA生成の偏りなどに強く依存するため、別ドメインや別構成では結果が変化する可能性があります。
ただし、本結果は単一PDFに対するクローズドなQA生成ベースの評価であり、一般的な検索性能を直接示すものではない点には注意が必要です。チャンク設計やデータ分布、QA生成の偏りなどに強く依存するため、別ドメインや別構成では結果が変化する可能性があります。7. なぜ、いま Harrier × Azure AI Search が“差がつく導入”なのか
まとめると、Harrier‑oss‑v1 と Azure AI Search の組み合わせは、“精度・コスト・多言語・導入しやすさ”をすべて踏まえた、次世代のベクトル検索・RAG 基盤として完成形に近い状態です。
- 高精度:Harrier 0.6B が text‑embedding 系を上回る精度
- 運用統制: 埋め込み実行基盤を自社管理でき、監査・閉域要件に合わせやすい
- スケール時の最適化余地: 利用量増加時にAPI従量コストの最適化余地が大きい
- 実装支援:当社では SplitSkill 設定から検索精度チューニングまで一気通貫でサポート
そこで当社はPoCで、精度・実質TCO・セキュリティを考慮し、最短で本番向き構成を見極めます。
「とりあえず導入」ではなく、「成果が出る構成」を。まずはご相談ください。
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事





この著者の保持資格