RAGをもっと信頼できるものにする方法~評価編~【第3回】
2026.01.22

目次
はじめに
MS開発部の松坂です。RAG(検索+生成)の正しさを上げるには、どこが良くてどこが弱いのかを切り分けられることが重要です。
そのための診断ツールが RAGChecker です。
第3回(評価編)は、RAGCheckerが提案する評価の考え方(回答をクレーム=主張に分解し、検索と生成を別々に診断)に沿って、C#コードで診断パイプラインを組み立て、非エンジニアにも伝わる出力まで仕上げます。
RAGCheckerはGitHub上でOSSとして公開され、論文や実装ガイドも整備されています。必要に応じて公式パッケージでの実行にも切り替え可能です。
RAGCheckerとは
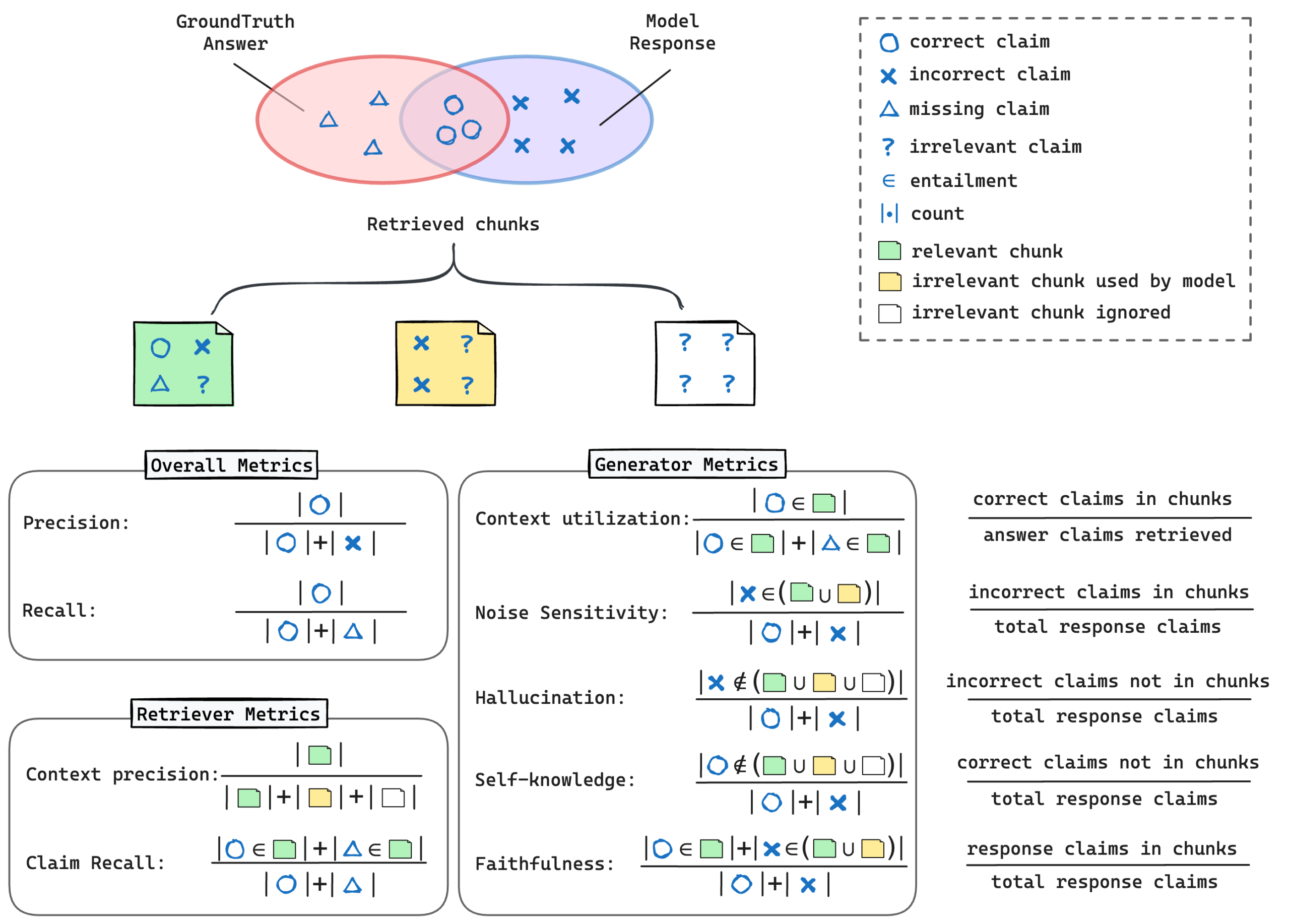
RAGCheckerは、回答を主張(claim)単位に分解して、Retriever(検索)とGenerator(生成)を別々に評価できるのが最大の特徴です。全体のPrecision/Recall/F1に加え、Claim Recall / Context Precision(検索)
Faithfulness / Hallucination / Context Utilization(生成)などの指標を提供します。これにより、「検索が原因か/生成が原因か」を切り分け、改善の当て所が明確になります。さらに、人手評価との相関が高いことも報告されています。
評価データを用意する
RAGCheckerが期待する最小の入力は、1問ごとに以下です。- query(質問)
- gt_answer(正解)
- response(RAGの実際の回答)
- retrieved_context(検索で拾ったチャンク配列:text / doc_id)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "results": [ { "query_id": "QA-0001", "query": "有休を取得する場合、申請はいつまでに行う必要がありますか?", "gt_answer": "取得希望日の3営業日前までが申請期限です。特例は部門長承認があれば可能です。", "response": "申請は5営業日前までです。特例は部門長承認で可です。", "retrieved_context": [ { "doc_id": "policy-v2025-01#12", "text": "申請期限は3営業日前。緊急時は部門長承認で当日可。" }, { "doc_id": "policy-v2023-09#05", "text": "旧版:申請期限は5営業日前。" } ] } ] } |
実務Tips:
- doc_idに版情報を含めておくと、旧版ヒットが原因の誤答を特定しやすくなります。
- 第2回でC#生成したgenerated_qas.json(question/answer)に、RAGの実行結果とretrieved_contextを結合して、この形式に整形します。入力仕様や具体例は公式/実践記事が参考になります
RAGCheckerの構成を4つの役割に分解してみる
RAGCheckerの実装や論文を追っていくと、 内部でやっていることは複雑そうに見えますが、役割ベースで見ると次の4段に整理できそうだと感じました。- クレーム抽出(Claim Extraction)
- 生成された回答文から、「事実として主張している文・断定表現」を抽出する
- 評価の最小単位を「文章全体」ではなく「クレーム」に分解する工程
- 含意判定(Entailment Judgment)
- 各クレームが、取得したドキュメントから裏付けられるかを判定する
- 支持されているのか、矛盾しているのか、根拠不明なのかを見るフェーズ
- 指標計算(Metric Calculation)
- 含意判定の結果をもとに、Faithfulness/Hallucination率/Coverageなどの評価指標を算出する
- 結果集約(Aggregation & Reporting)
- クレーム単位の評価をまとめ、全体スコア/警告コメント/デバッグ用の内訳といった形で人が読める結果に落とす
「LLMを評価する仕組み」というより「評価パイプライン」に近い構造をしているように思えます。
今回のC#実装では、この4つの役割をそのままコード構造に反映しました。
コード例(C#)
上記4つの役割をそのままコード構造に反映しました。①クレーム抽出:回答を“検証可能な主張”へ分割
回答文を意味のある主張に分割します(※JSON固定で返させ、後続処理を安定化)。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
public interface ILlmClient { Task<string> CompleteAsync(string prompt, object? options = null, CancellationToken ct = default); } public sealed class ClaimExtractor { private readonly ILlmClient _llm; public ClaimExtractor(ILlmClient llm) => _llm = llm; public async Task<ClaimRoot> ExtractAsync(string answer, CancellationToken ct = default) { if (string.IsNullOrWhiteSpace(answer)) return new ClaimRoot { Claims = new List<ClaimItem>() }; // 1) JSONオンリー & スキーマ宣言 string prompt = $$""" あなたはRAG評価用のアナライザです。以下の応答文を「検証可能な主張(クレーム)」に分割し、 **JSONのみ**で返してください。追加のテキストは一切禁止です。 # 制約 - 各クレームは 1 文、簡潔、事実検証可能 - 1クレームあたり 20〜120 文字程度 - 最大 8 件まで(過剰分割を避ける) # 出力スキーマ { "Claims": [ { "Claim": "..." } ] } # 応答文 {{answer}} """; var raw = await _llm.CompleteAsync( prompt, new { temperature = 0.1, max_tokens = 800 }, ct ); // 2) パース → 失敗したら自己修復 → それでもダメなら空で返す if (!TryDeserialize<ClaimRoot>(raw, out var result) || result?.Claims is null) { var repaired = await _llm.CompleteAsync($$""" 次の文字列は有効なJSONではありません。**有効なJSONのみ**に修復して返してください。 追加の説明やコードブロック記号は禁止です。 入力: {{raw}} """, new { temperature = 0.0, max_tokens = 800 }, ct); if (!TryDeserialize<ClaimRoot>(repaired, out result) || result?.Claims is null) result = new ClaimRoot { Claims = new List<ClaimItem>() }; } // 3) 後処理(空白除去・重複排除・最低限フィルタ) result.Claims = result.Claims .Where(c => !string.IsNullOrWhiteSpace(c.claim)) .Select(c => new ClaimItem { claim = c.claim.Trim() }) .DistinctBy(c => c.claim.ToLowerInvariant()) .Take(8) .ToList(); return result; } private static bool TryDeserialize<T>(string json, out T? value) { try { value = System.Text.Json.JsonSerializer.Deserialize<T>( json, new System.Text.Json.JsonSerializerOptions { PropertyNameCaseInsensitive = true, ReadCommentHandling = System.Text.Json.JsonCommentHandling.Skip, AllowTrailingCommas = true }); return value is not null; } catch { value = default; return false; } } } // 期待する型 public class ClaimRoot { public List<ClaimItem> Claims { get; set; } = new(); } public class ClaimItem { public string claim { get; set; } = ""; } |
②含意判定:クレーム×チャンクで“裏付くか”を判定
各クレームに対して、取得チャンクが**entail(裏付く)/contradict(矛盾)/unknown(根拠なし)**のどれかを返します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
public sealed class EntailmentJudge { private readonly ILlmClient _llm; public EntailmentJudge(ILlmClient llm) => _llm = llm; public async Task<ImplicationResponse> JudgeAsync(string claim, string chunk, CancellationToken ct = default) { if (string.IsNullOrWhiteSpace(claim) || string.IsNullOrWhiteSpace(chunk)) return new ImplicationResponse { label = "unknown", rationale = "入力不足" }; string prompt = $$""" 次の「クレーム」が「コンテキスト」で裏付くかどうかを厳密に判定してください。 **JSONのみ**で返し、追加のテキストは禁止です。 # 出力スキーマ { "label": "entailed|contradicted|unknown", "rationale": "簡潔な根拠" } # クレーム {{claim}} # コンテキスト {{chunk}} """; var raw = await _llm.CompleteAsync( prompt, new { temperature = 0.1, max_tokens = 700 }, ct ); if (!TryDeserialize<ImplicationResponse>(raw, out var result) || string.IsNullOrWhiteSpace(result?.label)) { var repaired = await _llm.CompleteAsync($$""" 次の文字列を有効なJSONに修復してください。**JSONのみ**で返してください。 入力: {{raw}} """, new { temperature = 0.0, max_tokens = 700 }, ct); if (!TryDeserialize<ImplicationResponse>(repaired, out result) || string.IsNullOrWhiteSpace(result?.label)) result = new ImplicationResponse { label = "unknown", rationale = "JSON解釈に失敗" }; } // ラベルの正規化(小文字化&許容外は unknown) var norm = (result!.label ?? "").Trim().ToLowerInvariant(); result.label = norm is "entailed" or "contradicted" or "unknown" ? norm : "unknown"; result.rationale = (result.rationale ?? "").Trim(); return result; } private static bool TryDeserialize<T>(string json, out T? value) { try { value = System.Text.Json.JsonSerializer.Deserialize<T>( json, new System.Text.Json.JsonSerializerOptions { PropertyNameCaseInsensitive = true, ReadCommentHandling = System.Text.Json.JsonCommentHandling.Skip, AllowTrailingCommas = true }); return value is not null; } catch { value = default; return false; } } } // 期待する型 public class ImplicationResponse { public string label { get; set; } = ""; // "entailed" | "contradicted" | "unknown" public string rationale { get; set; } = ""; // 簡潔な根拠 } |
- rationale(根拠説明)も保持しておくと、失敗例レビューやレポート説明責任に使えます。
- 並列実行でAPIコスト/レイテンシをコントロール。
例(Bugfix):”Enabled” ではなく “entailed” に正規化して比較する関数へ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
private bool IsEntailmentLabel(EntailmentLabel label, string labelStr) { var norm = (labelStr ?? "").Trim().ToLowerInvariant(); return label switch { EntailmentLabel.Entailed => norm == "entailed", EntailmentLabel.Contradicted => norm == "contradicted", EntailmentLabel.Unknown => norm == "unknown", _ => false }; } |
③指標計算:検索・生成を“別々に”見える化
- 生成側
- Faithfulness:クレームのうち根拠で裏付けられた割合
- HallucinationRate:unknownのみのクレーム割合(裏付け不在)
- 検索側
- ContextPrecision:取得チャンクのうち有効(entail(状況によりcontradictも含める))な割合
- ClaimRecall(本稿実装の扱い):応答クレームの裏付け率(=faithfulnessと同義に運用)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
/// <summary> /// クレーム(回答の主張)と取得チャンク(検索結果)の照合結果から、 /// RAG の検索性能・生成性能を示す指標をまとめて計算する。 /// </summary> private Metrics ComputeMetrics( List<ClaimChunkAnnotation> annotations, // 含意判定の結果(claim x chunk の3値) List<(string chunkId, string text)> chunks, List<ClaimItem> claims) { // ----------------------------- // 1. クレーム側の集計 // ----------------------------- int supportedClaims = 0; // entailed(裏付けられた) int contradictedClaims = 0; // contradicted(矛盾した) int unsupportedClaims = 0; // unknown(根拠が見つからない) foreach (var claim in claims) { // 指定クレームに関する全ての判定ラベルを取り出す var labels = annotations .Where(a => a.claim.claim == claim.claim) .Select(a => a.label) .ToList(); bool isSupported = labels.Any(l => IsEntailmentLabel(EntailmentLabel.Entailed, l)); bool isContradicted = labels.Any(l => IsEntailmentLabel(EntailmentLabel.Contradicted, l)); bool isAllUnknown = labels.Count > 0 && labels.All(l => IsEntailmentLabel(EntailmentLabel.Unknown, l)); if (isSupported) supportedClaims++; if (isContradicted) contradictedClaims++; if (isAllUnknown) unsupportedClaims++; } int totalClaims = claims.Count; // Faithfulness:回答の主張がどれだけ根拠で裏付けられていたか double faithfulness = totalClaims == 0 ? 1.0 : (double)supportedClaims / totalClaims; // Hallucination:裏付けが一切なかったクレームの割合 double hallucination = totalClaims == 0 ? 0.0 : (double)unsupportedClaims / totalClaims; // ClaimRecall(本実装では “裏付け率” と同義) double claimRecall = faithfulness; // ----------------------------- // 2. チャンク側の集計 // → Context Precision(ノイズの少なさ) // ----------------------------- int usefulChunks = 0; foreach (var chunk in chunks) { // この chunk が claim の裏付け or 矛盾判定に使われたか bool contributes = annotations.Any(a => a.chunk.Item1 == chunk.chunkId && (IsEntailmentLabel(EntailmentLabel.Entailed, a.label) || IsEntailmentLabel(EntailmentLabel.Contradicted, a.label))); if (contributes) usefulChunks++; } double contextPrecision = chunks.Count == 0 ? 0.0 : (double)usefulChunks / chunks.Count; // ----------------------------- // 3. 指標まとめ // ----------------------------- return new Metrics { ClaimRecall = claimRecall, ContextPrecision = contextPrecision, Faithfulness = faithfulness, HallucinationRate = hallucination, EntailedClaims = supportedClaims, ContradictedClaims = contradictedClaims, UnknownOnlyClaims = unsupportedClaims }; } |
④ 結果を集約して返す(1問ごと+全体サマリ)
実行ループでは、質問ごとの診断(Details)と全体サマリ(Summary)を構築します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
var summary = new RagSummary { TotalQueries = allDetails.Count, TotalClaims = allDetails.Sum(d => d.Claims.Count), AvgClaimRecall = allDetails.Count == 0 ? 0 : allDetails.Average(d => d.Metrics.ClaimRecall), AvgContextPrecision = allDetails.Count == 0 ? 0 : allDetails.Average(d => d.Metrics.ContextPrecision), AvgFaithfulness = allDetails.Count == 0 ? 0 : allDetails.Average(d => d.Metrics.Faithfulness), AvgHallucinationRate= allDetails.Count == 0 ? 0 : allDetails.Average(d => d.Metrics.HallucinationRate) }; var result = new RagEvaluationResult { Summary = summary, Details = allDetails }; return Ok(result); // ← まずは素の結果を返す(後述でLLM要約にも流用) |
いったん「RAGCheckerの出力はこんな感じ」(例)
公式RAGCheckerが返すイメージに寄せると、全体/Retriever/Generator/事例の4層で見るのが分かりやすいです。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "overall": { "precision": 0.74, "recall": 0.61, "f1": 0.67 }, "retriever": { "claim_recall": 0.62, "context_precision": 0.48 }, "generator": { "faithfulness": 0.86, "hallucination": 0.07, "noise_sensitivity": 0.18, "context_utilization": 0.55 }, "examples": [ { "query_id": "QA-0014", "query": "社内の有休取得ルールの申請期限は?", "diagnosis": { "retriever": "最新版チャンクの取りこぼし(旧版にヒット)", "generator": "特例の説明は忠実。期限は旧版に引っ張られて誤答" } } ] } |
- 全体:Precision, Recall, F1(クレーム単位)
- Retriever:Claim Recall(必要主張の取りこぼし率)、Context Precision(ノイズ混入度)
- Generator:Faithfulness(根拠への忠実性)、Hallucination(根拠なき主張)、Context Utilization(根拠の使い方) など
これらの定義・指標は公式と実装ガイドに整理されています。
- Claim Recallが低い×Faithfulness高い→ 検索が弱く、生成は“与えられた根拠には忠実”。検索強化が解。
- Hallucinationが高い→ 生成が根拠を無視/誤解。生成側のプロンプトやガードレールが解。
- Context Precisionが低い→ ノイズ多く生成が混乱。チャンク分割/インデックス/フィルタの見直しが解。
※本稿のC#実装(自作評価)はRAGCheckerの思想に沿って近い指標を出します。公式のRAGCheckerを使う場合は、同等の入力JSONをCLIやPython APIに渡して実行します。
(おまけ)LLMによる総合評価を自動生成する
非エンジニア向けに「良かった点/課題/リスク/推奨アクション(短期・中期)」まで一括でまとめた要約レポートを返すと、意思決定が速くなります。第1回で触れた「冒頭スコア(例:正しさ80%)」の根拠作りにも使えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
/// <summary> /// RAG評価サマリを、LLMで「非エンジニア向けの総合評価JSON」に要約する。 /// - 入力: RagEvaluationResult(平均スコアなど) /// - 出力: EvaluationFinalizePayload(生スコア + 要約 + 推奨アクション) /// </summary> private async Task<EvaluationFinalizePayload> LlmAnalysisGenerate(RagEvaluationResult ragEvaluation) { // 1) 入力のサニティチェック if (ragEvaluation?.Summary is null) throw new ArgumentException("ragEvaluation.Summary is required."); // 2) JSONオンリーを強制するプロンプト(スキーマ宣言付き) string analysisPrompt = $$""" あなたはRAG評価のアナリストです。以下の条件で、**JSONのみ**を返してください。 - 日本語で簡潔に - 追加のテキストや説明を一切含めない(JSON以外の文字は不可) - 数値は 0〜1 の小数で、必要に応じて本文では % 表現にしても良い # 出力スキーマ { "raw_results": { "context_precision": number, // 0..1 "context_recall": number, // 0..1(推定可) "faithfulness": number, // 0..1 "answer_relevancy": number, // 0..1(推定可) "overall_score": number // 0..1(合成スコア。根拠をsummaryで述べる) }, "llm_analysis": { "summary": string, // 全体傾向(良い点・注意点を1段落で) "strengths": string[], // 具体的な強み(2〜4個) "weaknesses": string[], // 具体的な弱み(2〜4個) "recommendations": string[] // 実務的アクション(3〜5個) } } # 入力データ(平均値) Faithfulness: {{ragEvaluation.Summary.AvgFaithfulness:0.###}} HallucinationRate: {{ragEvaluation.Summary.AvgHallucinationRate:0.###}} ClaimRecall: {{ragEvaluation.Summary.AvgClaimRecall:0.###}} ContextPrecision: {{ragEvaluation.Summary.AvgContextPrecision:0.###}} TotalQueries: {{ragEvaluation.Summary.TotalQueries}} TotalClaims: {{ragEvaluation.Summary.TotalClaims}} # 出力ポリシー - overall_score は、Faithfulness・ClaimRecall・ContextPrecision・(1-HallucinationRate) を総合して0..1で与える - strengths/weaknesses は具体名詞で簡潔に - recommendations は、誰が何をどう直すかが分かる粒度で """; // 3) LLM呼び出し(モデルは環境に合わせて) var raw = await _llm.CompleteAsync( analysisPrompt, new { temperature = 0.1, max_tokens = 1200 } // 低温度で再現性を高める ); // 4) JSONとしてパースを試みる(失敗したら一度だけ自己修復プロンプトで再試行) if (!TryDeserialize< EvaluationFinalizePayload >(raw, out var payload)) { var repaired = await _llm.CompleteAsync($$""" 次の文字列は、JSON以外の余分な文字を含むか、スキーマを満たしていません。 **有効なJSONのみ**に修復して返してください。追加説明は不可。 入力: ```text {{raw}} ``` 出力はJSONのみ。 """, new { temperature = 0.0, max_tokens = 1200 }); if (!TryDeserialize< EvaluationFinalizePayload >(repaired, out payload)) { // 5) それでも失敗するなら、最小のダミーJSONで返す(落ちない運用) payload = new EvaluationFinalizePayload { Status = "failed_json_parse", RawResults = new RawResult { ContextPrecision = ragEvaluation.Summary.AvgContextPrecision, ContextRecall = ragEvaluation.Summary.AvgClaimRecall, // 便宜上 Faithfulness = ragEvaluation.Summary.AvgFaithfulness, AnswerRelevancy = 0.0, OverallScore = ScoreHeuristic(ragEvaluation.Summary) }, LlmAnalysis = new LlmAnalysis { Summary = "LLM出力のJSON解釈に失敗したため、最小限の結果を返しました。", Strengths = new() { "暫定処理" }, Weaknesses = new() { "要約の欠落" }, Recommendations = new() { "プロンプトの見直し", "スキーマの明示", "再試行ロジックの強化" } }, AccuracyScore = (int)Math.Round(ScoreHeuristic(ragEvaluation.Summary) * 100), CompletedAt = DateTimeOffset.UtcNow.ToString("o") }; } } // 6) 仕上げ:AccuracyScoreやタイムスタンプなどを補完 payload!.AccuracyScore = (int)Math.Round( payload.RawResults.OverallScore * 100.0 ); payload.CompletedAt = DateTimeOffset.UtcNow.ToString("o"); payload.Status = "completed"; return payload; } // JSONの安全デシリアライズ(ロガー等は省略) private static bool TryDeserialize<T>(string json, out T? value) { try { value = JsonSerializer.Deserialize<T>(json, new JsonSerializerOptions { PropertyNameCaseInsensitive = true, ReadCommentHandling = JsonCommentHandling.Skip, AllowTrailingCommas = true }); return value is not null; } catch { value = default; return false; } } // 合成スコアの簡易ヒューリスティック(第1回のゲージにも流用可) private static double ScoreHeuristic(RagSummary s) { // 0.4*Faithfulness + 0.2*ClaimRecall + 0.2*ContextPrecision + 0.2*(1-Hallucination) var score = 0.40 * s.AvgFaithfulness + 0.20 * s.AvgClaimRecall + 0.20 * s.AvgContextPrecision + 0.20 * (1.0 - s.AvgHallucinationRate); return Math.Clamp(score, 0.0, 1.0); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "raw_results": { "context_precision": 0.48, "context_recall": 0.62, "faithfulness": 0.86, "answer_relevancy": 0.89, "overall_score": 0.80 }, "llm_analysis": { "summary": "生成は根拠に忠実で幻覚は低水準。一方、検索が旧版ヒットで取りこぼしが散見。", "strengths": ["幻覚率が低い", "回答の根拠説明が一貫している"], "weaknesses": ["最新版チャンクの取りこぼし", "ノイズ多めのチャンク混入"], "recommendations": [ "doc_idに版情報を付与し、最新版重みを強化", "チャンク粒度の見直し(短すぎ問題の解消)", "生成時は根拠引用を必須化し、曖昧時は不確実宣言" ] } } |
まとめ
第1回から第3回までを通して、RAGの品質を高めるためのサイクル 「測る → 直す → 伝える」 を実務で回すための具体策を紹介しました。
- RAGCheckerの考え方(クレーム単位の評価 & 検索と生成の切り分け)に沿うと、 どこから直すべきか(検索か、生成か)が一目で分かり、改善の優先順位が明確になります。
- 本記事のC#実装パイプラインでは、 回答からのクレーム抽出 → 含意判定(チャンク照合) → 指標計算 → 結果集約までを自動化。 JSON固定・低温度・自己修復の方針により、評価処理の安定性も高めています。
- 仕上げにLLMで総合評価レポートを生成すれば、 非エンジニアにも伝わる「読み物」として共有可能。 現場の意思決定に直結する〈良かった点/課題/推奨アクション/優先度〉をワンパッケージで配布できます。
-
公式のRAGCheckerを使う場合は、同等の入力JSONを
CLI/Python APIに渡すだけ。LlamaIndex連携も整備されており、 既存RAGの出力から評価形式へ変換する導入が容易です。
ここからは、まずは小さく始めて、効果を確認しながら広げていくのがおすすめです。
次のアクション(スモールスタート)
- 評価セットの拡充: 第2回のExpertGenQA(C#実装)で、想定質問のバリエーションと難易度を増やす (スタイル:ルール適用/シナリオ/用語解説を1~2問ずつ追加)。
- 評価の定期運用: 週次またはリリースごとにRAGChecker相当の評価を回し、 Claim Recall/Context Precision/Faithfulness/Hallucinationをダッシュボード化。
- 改善の反映: 指標に基づき、検索(インデックス/チャンク/再ランク/版管理)、 生成(根拠引用必須・不確実時の応答方針)の順で着手。改善後に再評価。
- 要約レポートの配布: LLMで総合評価(JSON)を生成し、非エンジニア向けに 「結論 → 影響 → 推奨アクション(短期/中期)」の順で共有。
参考
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事





この著者の保持資格