RAGをもっと信頼できるものにする方法~概要編~【第1回】
2026.01.20

目次
はじめに
MS開発部の松坂です。生成AIを業務に活用する企業が増える中で、「AIの答えは本当に正しいのか?」という不安は常につきまといます。
RAG(Retrieval-Augmented Generation)は、社内ドキュメントやナレッジを検索してから回答を生成する仕組みで、一般的な生成AIよりも根拠に基づく回答を返しやすいのが特徴です。
一方で、検索が適切でも生成段階で誤ることがあり、逆に生成がうまくても検索結果がズレていれば正しい答えにはなりません。
つまりRAGの品質は、「検索」と「生成」という2つの要素の組み合わせで決まります。
では、その精度はどのくらいなのでしょうか。 もしこちらの画像のように「このRAGは精度86%で高いです」といった形で、ざっくりでも数値と概要が把握できたら、安心感も改善の方向性もぐっと明確になりますよね。
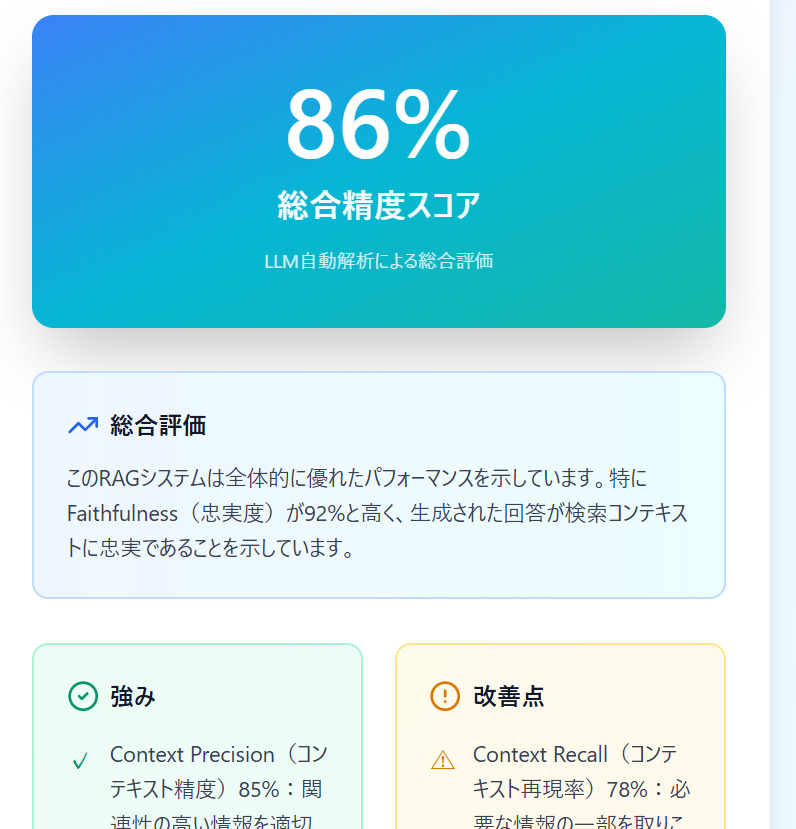 RAGの信頼性を高めるために重要なのは、
RAGの信頼性を高めるために重要なのは、「正しく測る」→「正しく直す」 というサイクルを回すことです。
本記事では、RAGの精度を%で“見える化”するための考え方と、その具体的な手順を紹介していきます。
RAGで起こりがちな課題
前章で触れたように、RAGの精度は「検索」と「生成」の両方に依存します。そしてこの2つは、どちらか一方がうまくいっても、最終的な回答が正しいとは限りません。
実際にRAGを業務で使い始めると、次のような課題に直面することが少なくありません。
これらはすべて、「精度を感覚ではなく、きちんと測る必要がある理由」でもあります。
- 検索の精度不足:関連情報がうまく取得できないと、回答の質が下がります。
- 生成モデルの幻覚(ハルシネーション):正しい情報があっても、モデルが誤った文章を作ることがあります。
- 長文回答の評価の難しさ:部分的に正しい/誤っているなど“グレー”なケースの把握が難しい点
- ビジネス上のリスク:誤情報が意思決定や顧客対応に影響
評価データの整備(どんな質問に、どんな回答が正解なのか) と
精度の見える化(検索と生成のどこに問題があるのかを切り分けること)
を、セットで考える必要があります。
品質を高めるための2つのアプローチ
前章で見た課題は、突き詰めると次の2つに集約できます。「そもそも、正しく答えられるはずの質問を用意できているか」
「どこで間違っているのかを、切り分けて把握できているか」
です。
RAGの品質を安定して高めるには、
この2点を押さえたうえで 「測る → 直す」 を回す必要があります。
そのための代表的なアプローチが、以下の2つです。
高品質な評価用Q&Aを用意する(ExpertGenQA)
専門ドキュメントに対して、少数の見本(few-shot)から網羅的で質の高いQ&Aを自動生成する方法です。 たとえば、次のような社内ドキュメントがあるとします。
たとえば、次のような社内ドキュメントがあるとします。本サービスでは、顧客データを暗号化して保存します。 データはAES-256方式で暗号化され、復号鍵はクラウドKMSで管理されます。 また、管理者権限を持つユーザーのみが復号処理を実行できます。ExpertGenQAを使うと、この文章をもとに、次のようなQ&Aを自動生成できます。
-
Q:顧客データはどのように保護されていますか?
A:AES-256方式で暗号化して保存され、復号鍵はクラウドKMSで管理されています。 -
Q:誰が顧客データを復号できますか?
A:管理者権限を持つユーザーのみが復号処理を実行できます。 -
Q:顧客データの暗号化方式は何ですか?
A:AES-256方式が使われています。
精度を“診断”して改善ポイントを特定(RAGChecker)
回答を“主張(クレーム)”の単位に分解し、検索と生成をそれぞれ評価します。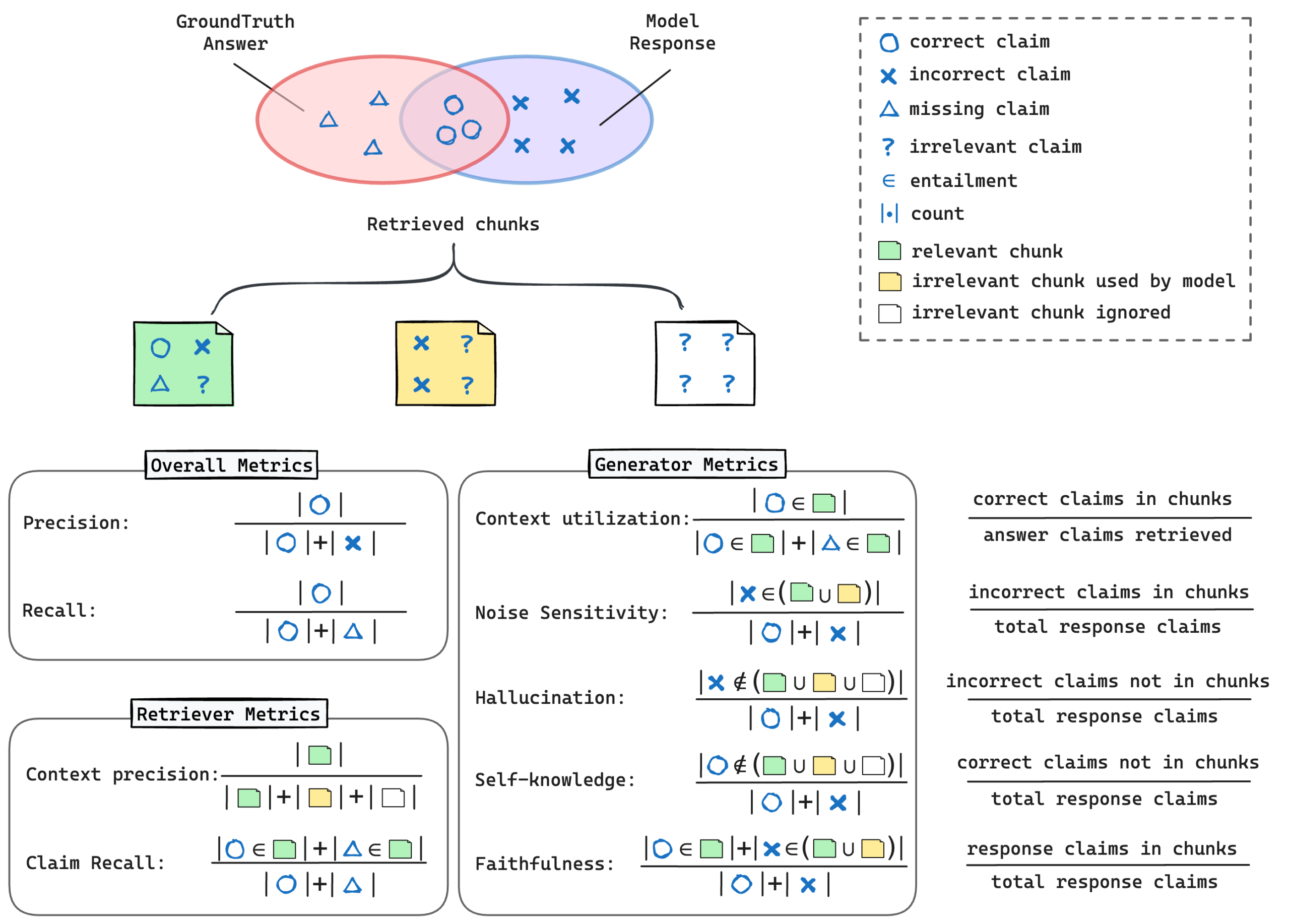 例)「検索が弱いので取りこぼしが多い/生成は概ね忠実だが根拠不足時に誤る」など、直すべき箇所が明確になります。
例)「検索が弱いので取りこぼしが多い/生成は概ね忠実だが根拠不足時に誤る」など、直すべき箇所が明確になります。このように、ドキュメントの内容をもとに「答えが明確な質問」をまとめて用意できるため、
RAGがどの情報を取りこぼしているのか、どこで誤解しているのかを定量的に評価できます。
※具体的にどのようなデータが出力されるかに関しては「RAGをもっと信頼できるものにする方法~評価編~【第3回】」をご覧ください。
全体の流れ(改善サイクル)
「品質を高めるための2つのアプローチ」で紹介した技術を用いることで以下の順番で継続的なサイクルを行います。- 評価用Q&A生成(ExpertGenQA)
- RAG構築・回答生成(Retriever→Generator)
- 精度診断(RAGCheckerでモジュール別+全体指標)
- 総合評価レポート(LLMで要約/意思決定向けに翻訳) → 結果を受けて、検索のチューニング/プロンプト改善/ガードレール追加などを実施。再度1~3へ。
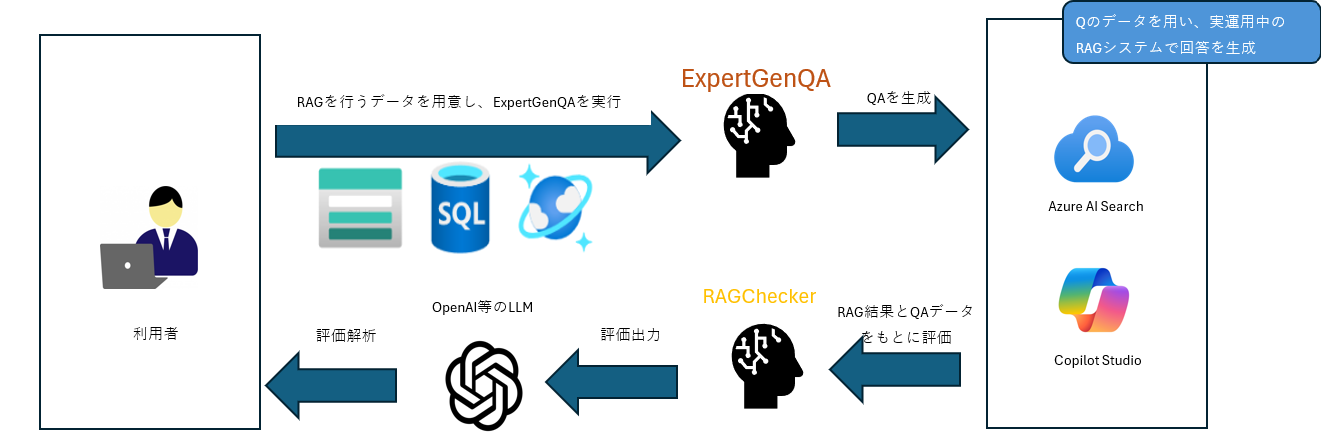 上の図は「何をどう進めるか」の全体像です。
上の図は「何をどう進めるか」の全体像です。ここからは、この流れを実際に動かしたらどんな出力が得られるのかを簡単な例で示します。
最後に、その出力をOpenAIなどのLLMで自然言語要約して、非エンジニアでも使いやすいレポートにするところまでお見せします。
具体例:総合評価レポートの作り方
入力:RAGCheckerの出力(例:Claim Recall 62%、Context Precision 48%、Hallucination 7% などの指標と、失敗例サンプル)
LLM要約のプロンプト例:
以下のRAG評価指標を読み取り、要件通りのJSONのみを返してください。
【入力の意味】
– Faithfulness(忠実度): 生成が検索コンテキストに忠実か
– HallucinationRate(幻覚率): 裏付けのない主張の割合
– ClaimRecall(クレーム再現率): 応答内クレームがコンテキストで裏付け可能な割合
– ContextPrecision(コンテキスト精度): 取得チャンクの有効割合
【出力フォーマット(JSONのみ / 追加のテキスト禁止)】
{…}
【入力データ(数値は0-1の小数、必要なら%で言及可)】
…
【作成方針】
– summary: 全体傾向を日本語で簡潔に。主要指標に触れる。
– strengths: 良い点を具体的に。日本語で箇条書き。
– weaknesses: 改善余地を具体的に。日本語で箇条書き。
– recommendations: 実務的な調整案(chunk_size/top_k/overlap/リランク/プロンプト等)を日本語で箇条書き。
– 数値は%表現に丸めてもよい(例: 92%)。
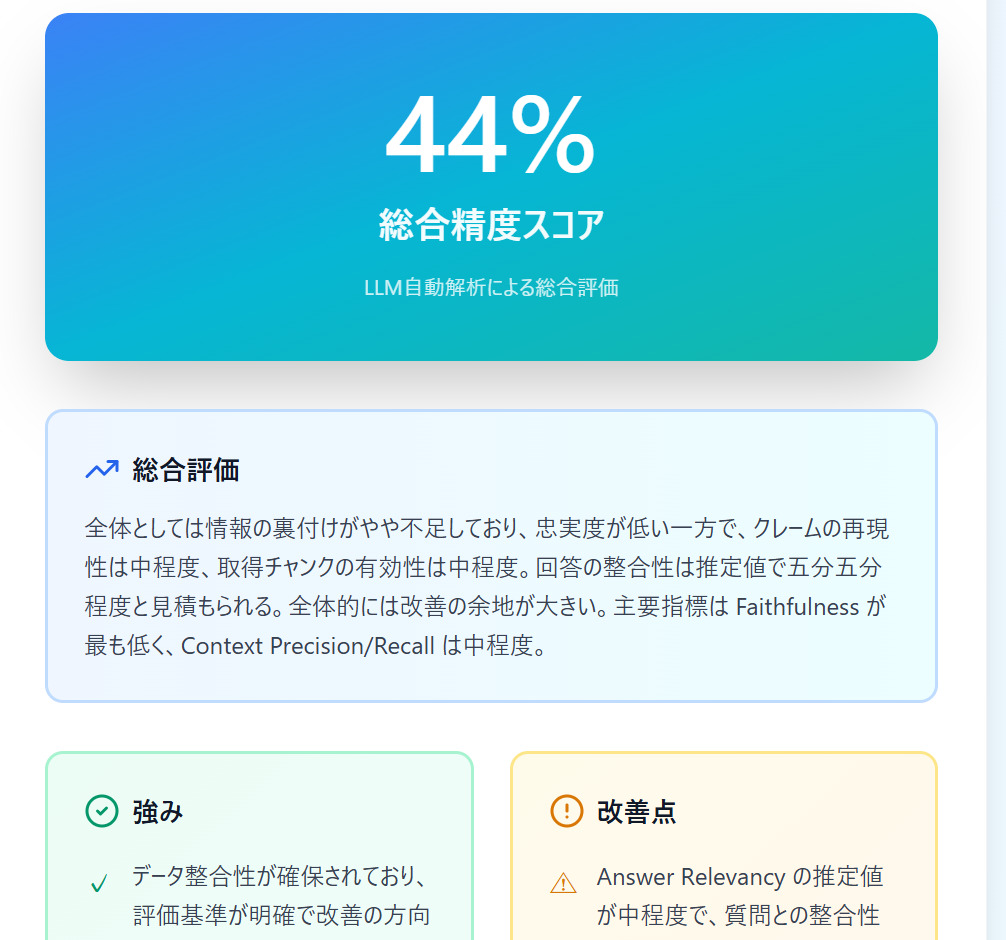 出力:
出力:要約:「回答の整合性は推定値で五分五分程度と見積もられる。全体的には改善の余地が大きい。」
強み:「データ整合性が確保されており、評価基準が明確で改善の方向性が把握できる。」
推奨アクション:「質問との整合性が不足する箇所がありそう」
このように、専門的な指標を“意思決定に使える言葉”へ翻訳することで、関係者が同じ目線で改善に取り組めます。
よくある改善パターン
RAGの精度を評価・診断すると、多くのケースで改善ポイントは大きく
「検索側」と「生成側」のどちらかに現れます。
以下は、ExpertGenQA と RAGChecker を使って評価した際に、
実務でよく見られる改善パターンの例です。
検索側の改善
検索精度に課題がある場合、「必要な情報が取れていない」「ノイズが多い」といった傾向が見られます。
- 対象文書の整理(重複・古い版の除去)
- チャンク分割の最適化(短すぎず長すぎず)
- ドメイン用語の同義語辞書/略語辞書の整備
生成側の改善
検索結果は十分でも、生成段階で回答が逸脱しているケースでは、
プロンプト設計やルール設定の見直しが有効です。
- 回答に根拠の文を明示的に引用するプロンプト設計
- 根拠が不十分な場合は「分からない」と答えるルールの付与
- 敏感領域(価格、法務、医療など)のガードレール強化
まとめ
RAGの信頼性を高める鍵は、評価用Q&Aの整備(ExpertGenQA)と精度の見える化(RAGChecker)、そして非エンジニアにも伝わる総合評価レポート(LLM要約)の三位一体です。この改善サイクルを回し続けることで、AIの答えを「安心して使える水準」へ引き上げられます。
次回(QA生成編)では、ExpertGenQAを使って評価や学習に役立つQ&Aを素早く用意する具体的な方法を紹介します。




以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事
この著者の保持資格