RAGをもっと信頼できるものにする方法~QA生成編~【第2回】
2026.01.21

はじめに
MS開発部の松坂です。最近、専門分野向けの質問・回答を効率よく作りたい場面が増えています。
例えば「社内マニュアルの内容を理解した人向けのテスト問題」や「特定技術のFAQ集」などです。
そこで注目されるのが ExpertGenQA というプロトコルです。
少数の専門家による良問・良答の例(few-shot)を参考にしつつ、文章から主要トピックを抽出して、スタイルごとの質問を自動生成できるのが特徴です。
論文ではトピック網羅率94.4%、retriever精度も大きく改善したという結果が報告されています。
https://arxiv.org/abs/2503.02948
第2回では、ExpertGenQAの考え方を整理したうえで、C#を使った最小構成の実装例を示します。
「専門家の知識をそのままQ&Aに変換したい」と考えている方に向けて、トピック抽出→質問生成→JSON出力までの流れを実践できます。
ExpertGenQAの概要
ExpertGenQAは、大学研究発のQA自動生成手法で、RAGのソースドキュメントを直接入力としてQAを生成する点が特徴です。
一般的な流れは以下の通りです。
- ドキュメント解析・チャンク分割
- トピック・概念の抽出
- 複数パターン(定義・手順・シナリオ等)のQA生成
構造化されていない自然文にも適用しやすいのが強みです。
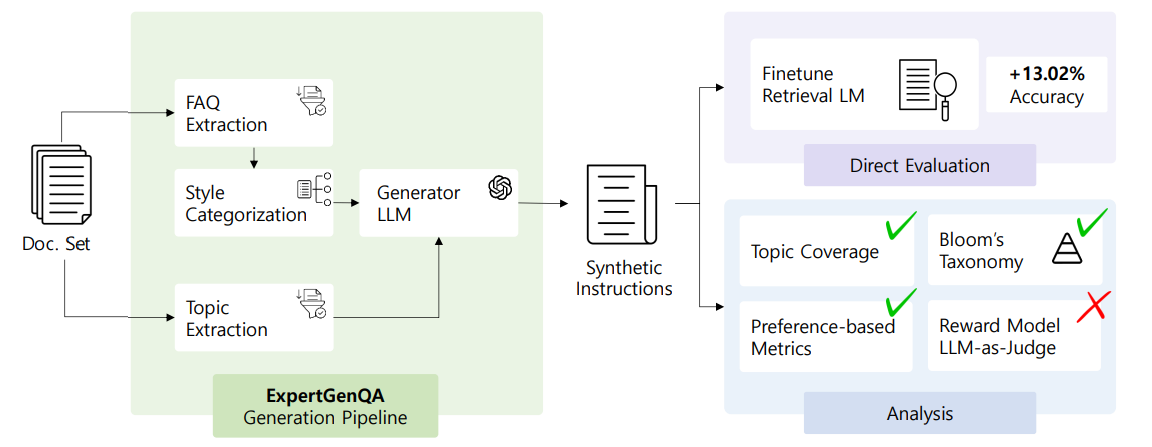
C#による自動QA生成の実装イメージ
ExpertGenQA風の自動QA生成フローをC#で表現します。上記の概要で説明した一般的な流れに沿って各項目を説明していきます。
ドキュメント解析・チャンク分割
多様なフォーマットを正規化して、意味が破綻しない粒度でオーバーラップ付きに分割し、後段(トピック抽出・QA生成)の精度を安定させます。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
// トピック出力スキーマ(構造化出力を前提) public record Topic(string Id, string Name, string Description, List<string> RepresentativeChunkIds); public interface ILlmClient { // モデルごとにStructured OutputやJSONモード等は内部で吸収する前提 Task<string> CompleteAsync(string systemPrompt, string userPrompt, object? options = null); } public class TopicExtractor { private readonly ILlmClient _llm; public TopicExtractor(ILlmClient llm) => _llm = llm; public async Task<List<Topic>> ExtractAsync(IEnumerable<DocChunk> chunks, int maxTopics = 30) { // 代表チャンク(先頭Nなど簡易サンプル。実運用はサンプリング/クラスタリング可) var sample = chunks.Take(200).Select(c => new { c.ChunkId, c.Text }).ToList(); var system = "あなたは技術文書から重複の少ない概念トピックを抽出する専門家です。"; var user = $@" 以下は文書チャンクのサンプルです。内容を俯瞰し、重複・冗長を避けた{maxTopics}件以内のトピックをJSONで返してください。 出力スキーマ: [ {{ ""id"": ""string"", ""name"": ""短い見出し"", ""description"": ""要点を2-3文で"", ""representative_chunk_ids"": [""chunk-id1"", ""chunk-id2""] }} ] ### チャンク(id: text 先頭部分) {string.Join("\n", sample.Select(s => $"{s.ChunkId}: {TrimForPrompt(s.Text, 500)}"))} 必須条件: - 同義語を統合し、粒度を揃える - 汎用・抽象的すぎる項目は避ける - 各トピックに代表チャンクIDを1-3件含める - JSON以外の出力は不要 "; var json = await _llm.CompleteAsync(system, user, new { temperature = 0.2, max_tokens = 1500 }); // JSONをパース(例:System.Text.Json) var topics = System.Text.Json.JsonSerializer.Deserialize<List<Topic>>(json) ?? new List<Topic>(); // 追加の重複除去等はアプリで実施 return topics; } private static string TrimForPrompt(string text, int max) => text.Length <= max ? text : text[..max]; } |
トピック抽出
チャンク集合から冗長性の少ない概念リストを作成し、後段のQA生成を網羅的かつ重複少なく誘導します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
// トピック出力スキーマ(構造化出力を前提) public record Topic(string Id, string Name, string Description, List<string> RepresentativeChunkIds); public interface ILlmClient { // モデルごとにStructured OutputやJSONモード等は内部で吸収する前提 Task<string> CompleteAsync(string systemPrompt, string userPrompt, object? options = null); } public class TopicExtractor { private readonly ILlmClient _llm; public TopicExtractor(ILlmClient llm) => _llm = llm; public async Task<List<Topic>> ExtractAsync(IEnumerable<DocChunk> chunks, int maxTopics = 30) { // 代表チャンク(先頭Nなど簡易サンプル。実運用はサンプリング/クラスタリング可) var sample = chunks.Take(200).Select(c => new { c.ChunkId, c.Text }).ToList(); var system = "あなたは技術文書から重複の少ない概念トピックを抽出する専門家です。"; var user = $@" 以下は文書チャンクのサンプルです。内容を俯瞰し、重複・冗長を避けた{maxTopics}件以内のトピックをJSONで返してください。 出力スキーマ: [ {{ ""id"": ""string"", ""name"": ""短い見出し"", ""description"": ""要点を2-3文で"", ""representative_chunk_ids"": [""chunk-id1"", ""chunk-id2""] }} ] ### チャンク(id: text 先頭部分) {string.Join("\n", sample.Select(s => $"{s.ChunkId}: {TrimForPrompt(s.Text, 500)}"))} 必須条件: - 同義語を統合し、粒度を揃える - 汎用・抽象的すぎる項目は避ける - 各トピックに代表チャンクIDを1-3件含める - JSON以外の出力は不要 "; var json = await _llm.CompleteAsync(system, user, new { temperature = 0.2, max_tokens = 1500 }); // JSONをパース(例:System.Text.Json) var topics = System.Text.Json.JsonSerializer.Deserialize<List<Topic>>(json) ?? new List<Topic>(); // 追加の重複除去等はアプリで実施 return topics; } private static string TrimForPrompt(string text, int max) => text.Length <= max ? text : text[..max]; } |
QA生成(定義・ルール・シナリオ)
トピックごとに**問の型(定義、手順、比較、シナリオ、制約/例外、否定確認 等)**を意図的に混ぜ、引用(citations)必須で外部知識混入を抑制します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
public record QaItem( string Id, string TopicId, string Question, string Answer, List<string> Citations, string Pattern, // "definition" | "procedure" | "scenario" | "comparison" | ... string Difficulty, // "beginner" | "intermediate" | "advanced" List<string> ChunkIds ); public class QaGenerator { private readonly ILlmClient _llm; public QaGenerator(ILlmClient llm) => _llm = llm; public async Task<List<QaItem>> GenerateForTopicAsync( Topic topic, IReadOnlyDictionary<string, DocChunk> chunkIndex, int perTopic = 6, string[] patterns = null!) { patterns ??= new[] { "definition", "procedure", "scenario", "comparison", "constraint", "negative_check" }; // 代表チャンク本文をまとめて根拠として提示 var grounds = topic.RepresentativeChunkIds .Where(chunkIndex.ContainsKey) .Select(id => new { id, text = chunkIndex[id].Text }) .ToList(); var system = "あなたは根拠テキストに**厳密に依拠**して良質なQAを作るアシスタントです。外部知識は禁止。"; var user = $@" トピック: - id: {topic.Id} - name: {topic.Name} - description: {topic.Description} 根拠テキスト(chunk_id: 内容抜粋): {string.Join("\n\n", grounds.Select(g => $"{g.id}:\n{TrimForPrompt(g.text, 1200)}"))} 要件: - 次のパターンを<strong>可能な範囲で均等</strong>に含めてQAを作成: {string.Join(", ", patterns)} - 各QAはJSON配列の要素として返す。スキーマ: {{ ""id"": ""string"", ""topic_id"": ""{topic.Id}"", ""question"": ""string"", ""answer"": ""string"", ""citations"": [""chunk-id1"", ""chunk-id2""], ""pattern"": ""one of patterns"", ""difficulty"": ""beginner|intermediate|advanced"", ""chunk_ids"": [""chunk-id1"", ""chunk-id2""] }} - **回答は引用チャンク内の情報のみ**で完結させる - **citations と chunk_ids は必ず1つ以上**、存在するIDのみ - {perTopic}件を上限とし、重複や言い換えの繰り返しは避ける - JSON以外の出力は不要 "; var json = await _llm.CompleteAsync(system, user, new { temperature = 0.3, max_tokens = 2000 }); var items = System.Text.Json.JsonSerializer.Deserialize<List<QaItem>>(json) ?? new List<QaItem>(); // バリデーション(疑似例) items = items .Where(i => i.Citations != null && i.Citations.All(chunkIndex.ContainsKey)) .Where(i => !string.IsNullOrWhiteSpace(i.Question) && !string.IsNullOrWhiteSpace(i.Answer)) .ToList(); return items; } private static string TrimForPrompt(string text, int max) => text.Length <= max ? text : text[..max]; } |
結果例
カレーに関するWikipediaのデータを用意し、こちらを読み込んでQAを生成してもらいました。
結果として、さまざまな方向によるQAが生成されることが確認できました。

まとめ
* 手動QA作成はスケールしにくく、RAG評価のボトルネックになりがち* ExpertGenQAのような自動QA生成は、評価データ整備を高速化
* C#環境でも十分に実装可能である
RAGを「作って終わり」にせず、
継続的に改善・検証できる体制づくりの一手として、自動QA生成は非常に有効です。
参考
以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事





この著者の保持資格