【Microsoft Azure】Microsoft Foundryの新しいエージェント評価機能Rubric Evaluatorを見てみる
2026.07.01

こんにちは、MS開発部の渋谷です。先日のMicrosoft Build 2026において、AIエージェントの開発、評価、および運用を統合的に支援するプラットフォームMicrosoft Foundryの最新機能が多数発表されました。AIエージェントを本番運用していくうえで考えないといけない課題の一つとして、変わりゆくコンテキストの中で、エージェントの安全性と品質をどのように評価・監視するかが挙げられます。汎用的なベンチマークや静的なテストコードでは、ビジネスごとに異なる複雑な要件を測定することは困難です。そこで、先日のMicrosoft Build2026では、Rubric Evaluatorが発表されました。今回は、このRubric Evaluatorの概要、開発者や運用チームにとってのうれしいポイントについて考えてみます。
これにより、白紙の状態から評価基準を設計する手間が省け、実運用データを組み込むことで、現実のユースケースに即した精度の高い評価基準を構築できます。
実際にFoundryでエバリュエーターを作成するときは、ビルド→評価→エバリュエーターのカタログと進んでいき、エバリュエーターの作成をクリックしてください。
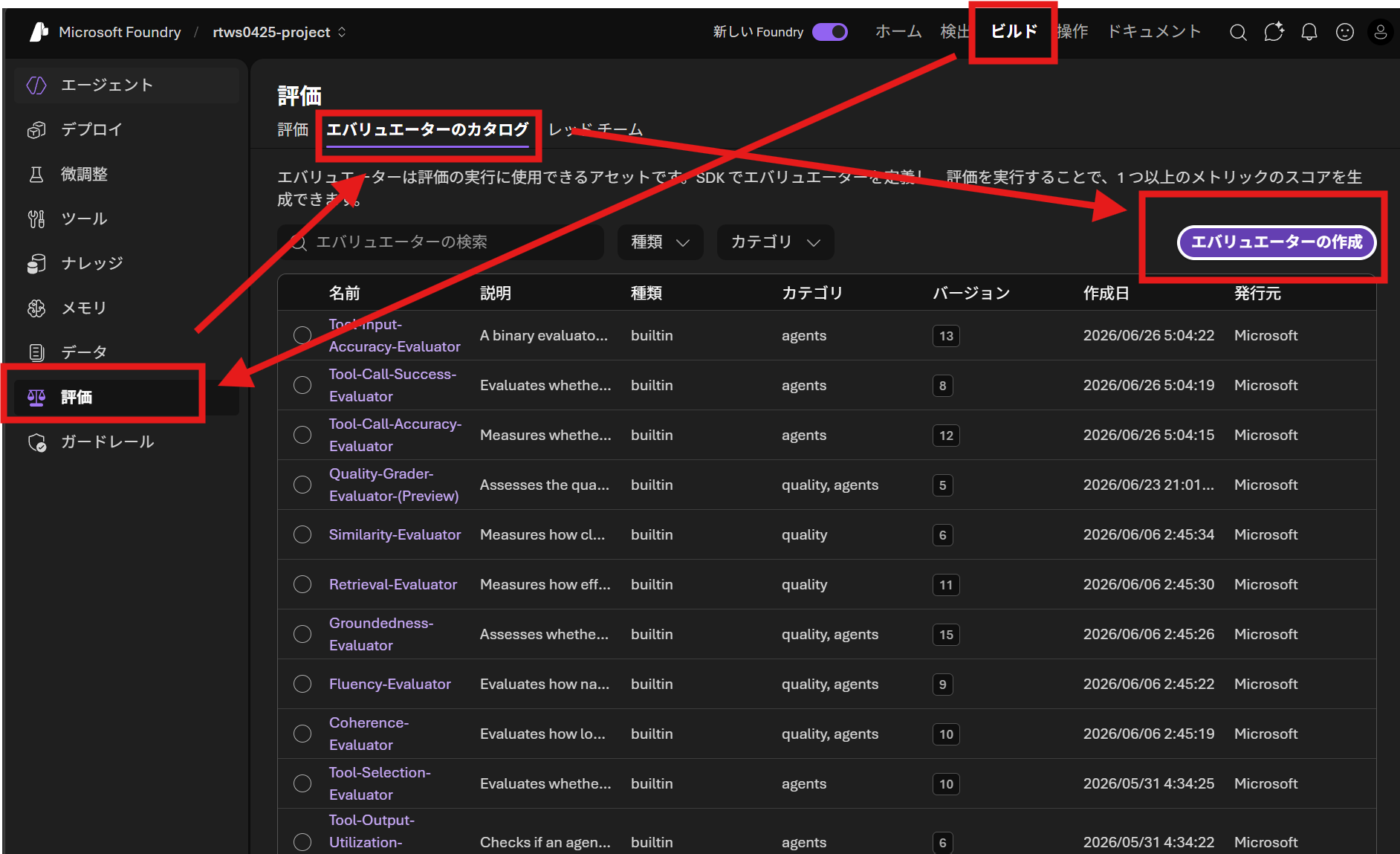 エバリュエーターの作成画面では、エバリュエーターの名前やモデル、対象エージェントを設定できます。画像の例では、gpt-5.4を使いrubric-agentというエージェントを対象にエバリュエーターを作成するように指定しています。
エバリュエーターの作成画面では、エバリュエーターの名前やモデル、対象エージェントを設定できます。画像の例では、gpt-5.4を使いrubric-agentというエージェントを対象にエバリュエーターを作成するように指定しています。
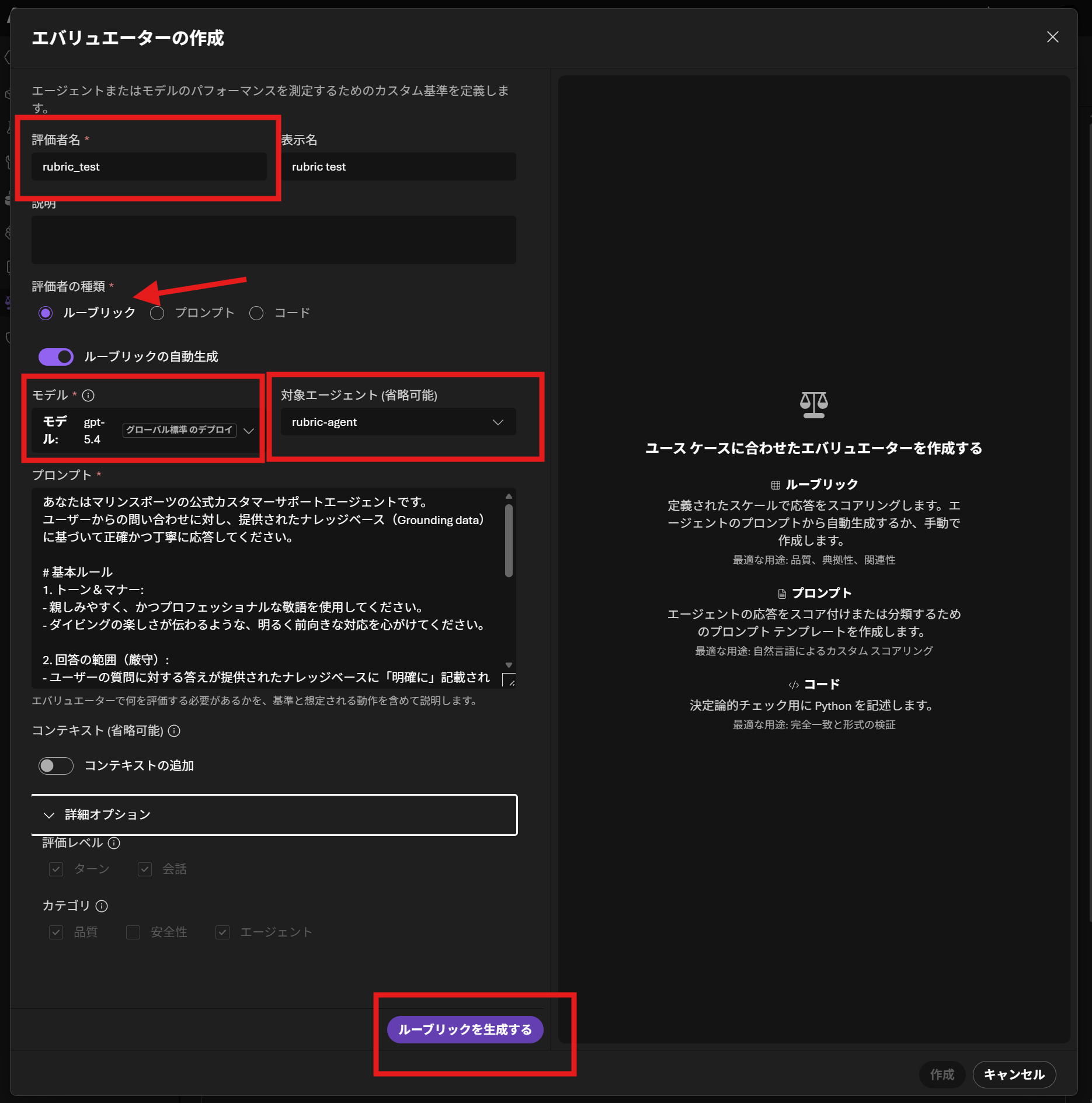 ルーブリックが生成されると、各種ディメンションの説明が生成され、この内容で良ければエバリュエーターを保存するをクリックすると準備完了です。
ルーブリックが生成されると、各種ディメンションの説明が生成され、この内容で良ければエバリュエーターを保存するをクリックすると準備完了です。
Rubric Evaluatorの概要
Rubric Evaluatorは、ユーザーが定義したカスタムの評価基準(これをルーブリックというみたいです)に基づいて、AIエージェントや基盤モデルの応答を採点するMicrosoft Foundry内の新しい評価ツールです。 LLMの判定モデルは、単一の応答、または複数ターンにわたる対話全体を読み込み、適用可能な各次元について1から5のスケールでスコアを付けます。その後、各次元のスコアとその重みに基づいて加重平均が計算され、最終的に0.0から1.0の範囲に正規化された総合スコアが算出されます。デフォルトの合格しきい値は0.5に設定されています。このしきい値以上のスコアであれば合格と判定され、下回れば不合格となります。品質基準を厳しくしたい場合はしきい値を上げ、許容度を高くしたい場合は下げるなど、用途に応じた柔軟な調整が可能です。さらに、判定結果には単なる数値だけでなく、なぜそのスコアになったのかを説明する詳細な理由がテキスト形式で出力されます。開発者にとってのうれしいポイント
コンテキストに応じた独自の評価基準を自動生成できる
最大の利点は、各エージェントのコンテキストに完全に適応したカスタム評価基準を、LLMを用いて自動生成できる点です。たとえば、社内ヘルプデスクのエージェントと、顧客向けの予約対応エージェントでは、求められる語調や正確性の基準が全く異なります。Rubric Evaluatorでは、そのエージェントに最適な評価基準を自動で作成できます。| 入力ソース | 説明 |
| Foundry Agent | Foundryに登録されている既存のエージェント。プロンプトエージェントの指示文や、ホストされたエージェントの説明文が自動的にコンテキストとして抽出されます。 |
| Agent System Prompt | エージェントの振る舞いを定義する指示文を直接ペーストします。Foundryに登録されていないエージェントを評価する場合に有効です。 |
| Reference Files | エージェントのコンテキストや期待される応答品質を説明するドキュメント、ナレッジベース、またはドメイン固有のガイドラインファイルです。 |
| Traces(トレース) | Application Insightsから収集された本番環境での実際の会話ログです。上記のいずれかの入力ソースと組み合わせることで、実際の使用状況に基づいたより実践的な基準を作成できます。 |
複数ターンの対話への対応
これまでの単純な評価ツールは、単一のプロンプトと応答の評価を前提としており、対話型エージェントの実態には即していませんでした。Rubric Evaluatorは複数ターンにわたる会話全体の評価に正式に対応しています。 これにより、ユーザーとの長い会話の中でコンテキストが正しく維持されているか、段階的な推論が一貫しているか、そして複数ステップのツール呼び出しを経て最終的なタスクが完遂されたかといった、エージェント特有の複雑な挙動を正確に評価できます。会話が蓄積されることで初めて表面化する品質の低下や安全性の問題も、この機能によって捉えることが可能です。判定モデルの選定とRubric Evaluatorの始め方
推論能力とコストのバランスから、次の表に示したモデルをエバリュエーターとして使用することを推奨しています。特に複雑な推論を必要とする評価には、強力な推論能力を持つ上位モデルの利用が適しています。| モデルの推奨度 | 対象モデル | 備考 |
| 推奨(最高品質) | GPT-5.5, GPT-5.4, GPT-5.2 | 最も精度の高い評価結果を提供します。 |
| 推奨(最適バランス) | GPT-5.4-mini, GPT-5.4-nano | パフォーマンスとコストのバランスが最も良く、大規模な継続的評価に適しています。 |
| 許容範囲 | GPT-4.1, GPT-4o | 評価タスクに利用可能ですが、最新モデルに比べると精度が劣る場合があります。 |
| 非推奨 | GPT-4o-mini | 新しいモデルと比較して明らかに信頼性の低いスコアを算出する傾向があるため、利用は避けるべきです。 |
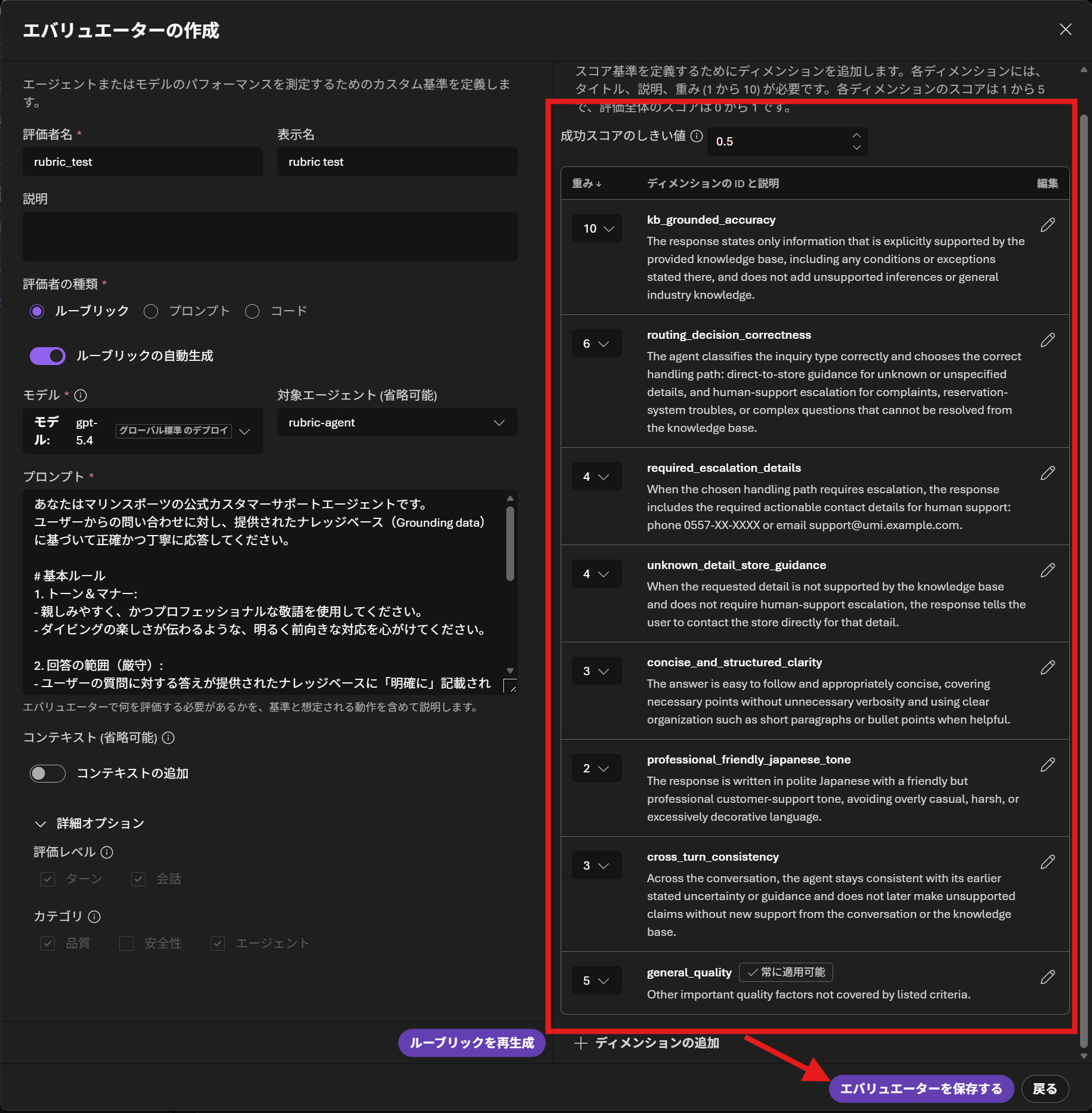
エバリュエーターの作成画面では、エバリュエーターの名前やモデル、対象エージェントを設定できます。画像の例では、gpt-5.4を使いrubric-agentというエージェントを対象にエバリュエーターを作成するように指定しています。
ルーブリックが生成されると、各種ディメンションの説明が生成され、この内容で良ければエバリュエーターを保存するをクリックすると準備完了です。
まとめ
Microsoft Build 2026で発表されたRubric Evaluatorは、AIエージェントの品質と安全性を評価するという複雑な課題に対し、静的なベンチマークに依存するのではなく、各エージェントの特有のコンテキストから自動生成される適応型の評価基準を持つことやスコアだけでなく、人間が読んで理解できる理由を提示してデバッグを加速させること、そして、その評価プロセスがインテリジェントなサンプリングやAgent Optimizerによる自律的な改善ループ、本番環境の継続的モニタリングと直接連動していることといった機能を提供します。これらは、AIアプリケーションを単なるプロトタイプから、エンタープライズで使えるエージェントを開発するのに役に立つことになるでしょう。以上、最後までご愛読いただき
ありがとうございました。
お問い合わせは、
以下のフォームへご連絡ください。
関連記事





この著者の保持資格